иҜҰи§ЈеӨ§ж•°жҚ®зҡ„жҖқжғіеҪўжҲҗдёҺд»·еҖјз»ҙеәҰ
ж—¶й—ҙ:14-07-09 ж Ҹзӣ®:еӨ§ж•°жҚ® дҪңиҖ…:зҲұиҜҙдә‘зҪ‘ иҜ„и®ә:0 зӮ№еҮ»: 1,614 ж¬Ў
жң¬ж–Үж Үзӯҫпјҡ еӨ§ж•°жҚ® , еӨ§ж•°жҚ® , еӨ§ж•°жҚ®ж—¶д»Ј
гҖҖгҖҖжҜ”еҰӮз»ҸжөҺдёҠпјҢй»„д»Ғе®Үе…Ҳз”ҹеҜ№е®Ӣжңқз»ҸжөҺзҡ„еҲҶжһҗдёӯеҸ‘зҺ°дәҶвҖңж•°зӣ®еӯ—з®ЎзҗҶвҖқ(еҚіе®ҡйҮҸеҲҶжһҗ)зҡ„е№ҝжіӣеә”з”Ё(еҸҜжғңзҺӢе®үзҹіеҸҳжі•жңүе§Ӣж— з»Ҳ)гҖӮеҸҲеҰӮеҶӣдәӢпјҢвҖңеҗ‘жһ—еҪӘеӯҰд№ ж•°жҚ®жҢ–жҺҳвҖқзҡ„жЎҘж®өдёҚи®әзңҹеҒҮпјҢе…¶иғҢеҗҺйҮҸеҢ–еҲҶжһҗзҡ„жҖқжғіж— з–‘жңүе…¶зҺ°е®һеҹәзЎҖпјҢиҖҢиҝҷдёҖеҹәзЎҖз”ҡиҮіеҸҜд»ҘеӣһжҺЁеҲ°2000еӨҡе№ҙеүҚпјҢеӯҷиҶ‘жӯЈжҳҜйҖҡиҝҮзј–йҖ вҖңеҚҒдёҮзҒ¶еҮҸеҲ°дә”дёҮзҒ¶еҶҚеҮҸеҲ°дёүдёҮзҒ¶вҖқзҡ„ж•°жҚ®гҖҒеҲ©з”Ёеәһ涓зҡ„йҮҸеҢ–еҲҶжһҗд№ жғҜеҜ№е…¶иҝӣиЎҢиҜұжқҖгҖӮ
гҖҖгҖҖеҲ°дёҠдё–зәӘ50-60е№ҙд»ЈпјҢзЈҒеёҰеҸ–д»Јз©ҝеӯ”еҚЎзүҮжңәпјҢеҗҜеҠЁдәҶж•°жҚ®еӯҳеӮЁзҡ„йқ©е‘ҪгҖӮзЈҒзӣҳй©ұеҠЁеҷЁйҡҸеҚіеҸ‘жҳҺпјҢе®ғеёҰжқҘзҡ„жңҖеӨ§жғіиұЎз©әй—ҙ并дёҚжҳҜе®№йҮҸпјҢиҖҢжҳҜйҡҸжңәиҜ»еҶҷзҡ„иғҪеҠӣпјҢиҝҷдёҖдёӢеӯҗи§Јж”ҫдәҶж•°жҚ®е·ҘдҪңиҖ…зҡ„жҖқз»ҙжЁЎејҸпјҢејҖе§Ӣж•°жҚ®зҡ„йқһзәҝжҖ§иЎЁиҫҫе’Ңз®ЎзҗҶгҖӮж•°жҚ®еә“еә”иҝҗиҖҢз”ҹпјҢд»ҺеұӮж¬ЎеһӢж•°жҚ®еә“(IBMдёәйҳҝжіўзҪ—зҷ»жңҲи®ҫи®Ўзҡ„еұӮж¬ЎеһӢж•°жҚ®еә“иҝ„д»Ҡд»ҚеңЁе»әиЎҢдҪҝз”Ё)пјҢеҲ°зҪ‘зҠ¶ж•°жҚ®еә“пјҢеҶҚеҲ°зҺ°еңЁйҖҡз”Ёзҡ„е…ізі»ж•°жҚ®еә“гҖӮдёҺж•°жҚ®з®ЎзҗҶеҗҢж—¶еҸ‘жәҗзҡ„жҳҜеҶізӯ–ж”ҜжҢҒзі»з»ҹ(DSS)пјҢ80е№ҙд»Јжј”еҸҳеҲ°е•ҶдёҡжҷәиғҪ(BI)е’Ңж•°жҚ®д»“еә“пјҢејҖиҫҹдәҶж•°жҚ®еҲҶжһҗвҖ”вҖ”д№ҹе°ұжҳҜдёәж•°жҚ®иөӢдәҲж„Ҹд№үвҖ”вҖ”зҡ„йҒ“и·ҜгҖӮ

гҖҖгҖҖйӮЈдёӘж—¶д»Јиҝҗз”Ёж•°жҚ®з®ЎзҗҶе’ҢеҲҶжһҗжңҖеҺүе®ізҡ„жҳҜе•ҶдёҡгҖӮ第дёҖдёӘж•°жҚ®д»“еә“жҳҜдёәе®қжҙҒеҒҡзҡ„пјҢ第дёҖдёӘеӨӘеӯ—иҠӮзҡ„ж•°жҚ®д»“еә“жҳҜеңЁжІғе°”зҺӣгҖӮжІғе°”зҺӣзҡ„е…ёеһӢеә”з”ЁжҳҜдёӨдёӘпјҡдёҖжҳҜеҹәдәҺretaillinkзҡ„дҫӣеә”й“ҫдјҳеҢ–пјҢжҠҠж•°жҚ®дёҺдҫӣеә”е•Ҷе…ұдә«пјҢжҢҮеҜје®ғ们зҡ„дә§е“Ғи®ҫи®ЎгҖҒз”ҹдә§гҖҒе®ҡд»·гҖҒй…ҚйҖҒгҖҒиҗҘй”Җзӯүж•ҙдёӘжөҒзЁӢпјҢеҗҢж—¶дҫӣеә”е•ҶеҸҜд»ҘдјҳеҢ–еә“еӯҳгҖҒеҸҠж—¶иЎҘиҙ§;дәҢжҳҜиҙӯзү©зҜ®еҲҶжһҗпјҢд№ҹе°ұжҳҜеёёиҜҙзҡ„е•Өй…’еҠ е°ҝеёғгҖӮе…ідәҺе•Өй…’еҠ е°ҝеёғпјҢеҮ д№ҺжүҖжңүзҡ„иҗҘй”Җд№ҰйғҪиЁҖд№ӢеҮҝеҮҝпјҢжҲ‘е‘ҠиҜүеӨ§е®¶пјҢжҳҜTeradataзҡ„дёҖдёӘз»ҸзҗҶзј–зҡ„пјҢдәәзұ»еҺҶеҸІдёҠд»ҺжІЎжңүеҸ‘з”ҹиҝҮпјҢдҪҶжҳҜпјҢе…Ҳж•ҷиӮІеёӮеңәпјҢеҶҚ收иҺ·еёӮеңәпјҢе®ғжҳҜжңүеҠҹзҡ„гҖӮ
гҖҖгҖҖд»…ж¬ЎдәҺжІғе°”зҺӣзҡ„д№җиҙӯ(Tesco)пјҢејәеңЁе®ўжҲ·е…ізі»з®ЎзҗҶ(CRM)пјҢз»ҶеҲҶе®ўжҲ·зҫӨпјҢеҲҶжһҗе…¶иЎҢдёәе’Ңж„ҸеӣҫпјҢеҒҡзІҫеҮҶиҗҘй”ҖгҖӮ
гҖҖгҖҖиҝҷдәӣйғҪеҸ‘з”ҹеңЁ90е№ҙд»ЈгҖӮ00е№ҙд»Јж—¶пјҢз§‘з ”дә§з”ҹдәҶеӨ§йҮҸзҡ„ж•°жҚ®пјҢеҰӮеӨ©ж–Үи§ӮжөӢгҖҒзІ’еӯҗзў°ж’һпјҢж•°жҚ®еә“еӨ§жӢҝеҗүе§ҶВ·ж јйӣ·зӯүжҸҗеҮәдәҶ第еӣӣиҢғејҸпјҢжҳҜж•°жҚ®ж–№жі•и®әзҡ„дёҖж¬ЎжҸҗеҚҮгҖӮеүҚдёүдёӘиҢғејҸжҳҜе®һйӘҢ(дјҪеҲ©з•Ҙд»Һж–ңеЎ”еҫҖдёӢжү”)пјҢзҗҶи®ә(зүӣйЎҝиў«иӢ№жһңз ёеҮәзҒөж„ҹпјҢеҪўжҲҗз»Ҹе…ёзү©зҗҶеӯҰе®ҡеҫӢ)пјҢжЁЎжӢҹ(зІ’еӯҗеҠ йҖҹеӨӘиҙөпјҢж ёиҜ•йӘҢеӨӘи„ҸпјҢдәҺжҳҜд№Һз”Ёи®Ўз®—д»Јжӣҝ)гҖӮ第еӣӣиҢғејҸжҳҜж•°жҚ®жҺўзҙўгҖӮиҝҷе…¶е®һд№ҹдёҚжҳҜж–°йІңзҡ„пјҢејҖжҷ®еӢ’ж №жҚ®еүҚдәәеҜ№иЎҢжҳҹдҪҚзҪ®зҡ„и§ӮжөӢж•°жҚ®жӢҹеҗҲеҮәжӨӯеңҶиҪЁйҒ“пјҢе°ұжҳҜж•°жҚ®ж–№жі•гҖӮдҪҶжҳҜеҲ°90е№ҙд»Јзҡ„ж—¶еҖҷпјҢз§‘з ”ж•°жҚ®е®һеңЁеӨӘеӨҡдәҶпјҢж•°жҚ®жҺўзҙўжҲҗдёәжҳҫеӯҰгҖӮеңЁзҺ°д»Ҡзҡ„еӯҰ科йҮҢпјҢжңүдёҖеҜ№еӯӘз”ҹе…„ејҹпјҢи®Ўз®—XXеӯҰе’ҢXXдҝЎжҒҜеӯҰпјҢеүҚиҖ…жҳҜжЁЎжӢҹ/и®Ўз®—иҢғејҸпјҢеҗҺиҖ…жҳҜж•°жҚ®иҢғејҸпјҢеҰӮи®Ўз®—з”ҹзү©еӯҰе’Ңз”ҹзү©дҝЎжҒҜеӯҰгҖӮжңүж—¶еҖҷи®Ўз®—XXеӯҰеҢ…еҗ«дәҶж•°жҚ®иҢғејҸпјҢеҰӮи®Ўз®—зӨҫдјҡеӯҰгҖҒи®Ўз®—е№ҝе‘ҠеӯҰгҖӮ
гҖҖгҖҖ2008е№ҙе…ӢйҮҢж–ҜВ·е®үеҫ·жЈ®(й•ҝе°ҫзҗҶи®әзҡ„дҪңиҖ…)еңЁгҖҠиҝһзәҝгҖӢжқӮеҝ—еҶҷдәҶдёҖзҜҮгҖҠзҗҶи®әзҡ„з»Ҳз»“гҖӢпјҢеј•иө·иҪ©з„¶еӨ§жіўгҖӮд»–дё»иҰҒзҡ„и§ӮзӮ№жҳҜжңүдәҶж•°жҚ®пјҢе°ұдёҚиҰҒжЁЎеһӢдәҶпјҢжҲ–иҖ…еҫҲйҡҫиҺ·еҫ—е…·жңүеҸҜи§ЈйҮҠжҖ§зҡ„жЁЎеһӢпјҢйӮЈд№ҲжЁЎеһӢжүҖд»ЈиЎЁзҡ„зҗҶи®әд№ҹжІЎжңүж„Ҹд№үдәҶгҖӮи·ҹеӨ§е®¶иҜҙдёҖдёӢж•°жҚ®гҖҒжЁЎеһӢе’ҢзҗҶи®әгҖӮеӨ§е®¶е…ҲзңӢдёӘзІ—зіҷзҡ„еӣҫгҖӮ
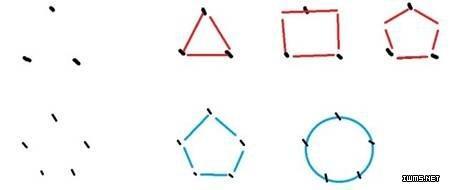
гҖҖгҖҖйҰ–е…ҲпјҢжҲ‘们еңЁи§ӮеҜҹе®ўи§Ӯдё–з•ҢдёӯйҮҮйӣҶдәҶдёүдёӘзӮ№зҡ„ж•°жҚ®пјҢж №жҚ®иҝҷдәӣж•°жҚ®пјҢеҸҜд»ҘеҜ№е®ўи§Ӯдё–з•ҢжңүдёӘзҗҶи®әеҒҮи®ҫпјҢз”ЁдёҖдёӘз®ҖеҢ–зҡ„жЁЎеһӢжқҘиЎЁзӨәпјҢжҜ”еҰӮиҜҙдёүи§’еҪўгҖӮеҸҜд»ҘжңүжӣҙеӨҡзҡ„жЁЎеһӢпјҢеҰӮеӣӣиҫ№еҪўпјҢдә”иҫ№еҪўгҖӮйҡҸзқҖи§ӮеҜҹзҡ„ж·ұе…ҘпјҢеҸҲйҮҮйӣҶдәҶдёӨдёӘзӮ№пјҢиҝҷж—¶еҸ‘зҺ°дёүи§’еҪўгҖҒеӣӣиҫ№еҪўзҡ„жЁЎеһӢйғҪжҳҜй”ҷзҡ„пјҢдәҺжҳҜзЎ®е®ҡжЁЎеһӢдёәдә”иҫ№еҪўпјҢиҝҷдёӘжЁЎеһӢеҸҚжҳ зҡ„дё–з•Ңе°ұеңЁйӮЈдёӘдә”иҫ№еҪўйҮҢпјҢж®ҠдёҚзҹҘзңҹжӯЈзҡ„ж—¶й—ҙжҳҜеңҶеҪўгҖӮ
гҖҖгҖҖеӨ§ж•°жҚ®ж—¶д»Јзҡ„й—®йўҳжҳҜж•°жҚ®жҳҜеҰӮжӯӨзҡ„еӨҡгҖҒжқӮпјҢе·Із»Ҹж— жі•з”Ёз®ҖеҚ•гҖҒеҸҜи§ЈйҮҠзҡ„жЁЎеһӢжқҘиЎЁиҫҫпјҢиҝҷж ·пјҢж•°жҚ®жң¬иә«жҲҗдәҶжЁЎеһӢпјҢдёҘж јең°иҜҙпјҢж•°жҚ®еҸҠеә”з”Ёж•°еӯҰ(е°Өе…¶жҳҜз»ҹи®ЎеӯҰ)еҸ–д»ЈдәҶзҗҶи®әгҖӮе®үеҫ·жЈ®з”Ёи°·жӯҢзҝ»иҜ‘зҡ„дҫӢеӯҗпјҢз»ҹдёҖзҡ„з»ҹи®ЎеӯҰжЁЎеһӢеҸ–д»ЈдәҶеҗ„з§ҚиҜӯиЁҖзҡ„зҗҶи®ә/жЁЎеһӢ(еҰӮиҜӯжі•)пјҢиғҪд»ҺиӢұж–Үзҝ»иҜ‘еҲ°жі•ж–ҮпјҢе°ұиғҪд»Һз‘һе…ёж–Үзҝ»иҜ‘еҲ°дёӯж–ҮпјҢеҸӘиҰҒжңүиҜӯж–ҷж•°жҚ®гҖӮи°·жӯҢз”ҡиҮіиғҪзҝ»иҜ‘е…ӢиҺұиҙЎиҜӯ(StarTrekйҮҢзј–еҮәжқҘзҡ„иҜӯиЁҖ)гҖӮе®үеҫ·жЈ®жҸҗеҮәдәҶиҰҒзӣёе…іжҖ§дёҚиҰҒеӣ жһңжҖ§зҡ„й—®йўҳпјҢд»ҘеҗҺиҲҚжҒ©дјҜж ј(дёӢйқўз§°д№ӢдёәиҖҒиҲҚ)еҸӘжҳҜжӢҫдәәзүҷж…§дәҶгҖӮ
гҖҖгҖҖеҪ“然пјҢ科еӯҰз•ҢдёҚи®ӨеҗҢгҖҠзҗҶи®әзҡ„з»Ҳз»“гҖӢпјҢи®Өдёә科еӯҰ家зҡ„зӣҙи§үгҖҒеӣ жһңжҖ§гҖҒеҸҜи§ЈйҮҠжҖ§д»ҚжҳҜдәәзұ»иҺ·еҫ—зӘҒз ҙзҡ„йҮҚиҰҒеӣ зҙ гҖӮжңүдәҶж•°жҚ®пјҢжңәеҷЁеҸҜд»ҘеҸ‘зҺ°еҪ“еүҚзҹҘиҜҶз–ҶеҹҹйҮҢйқўйҡҗи—Ҹзҡ„жңӘзҹҘйғЁеҲҶгҖӮиҖҢжІЎжңүжЁЎеһӢпјҢзҹҘиҜҶз–Ҷеҹҹзҡ„дёҠйҷҗе°ұжҳҜжңәеҷЁзәҝжҖ§еўһй•ҝзҡ„и®Ўз®—еҠӣпјҢе®ғдёҚиғҪжү©еұ•еҲ°ж–°зҡ„з©әй—ҙгҖӮеңЁдәәзұ»еҺҶеҸІдёҠпјҢжҜҸдёҖж¬ЎзҹҘиҜҶз–Ҷеҹҹзҡ„и·Ёи¶ҠејҸжӢ“еұ•йғҪжҳҜз”ұеӨ©жүҚе’Ң他们зҡ„зҗҶи®әзҺҮе…Ҳеҗ№иө·зҡ„еҸ·и§’гҖӮ
гҖҖгҖҖ2010е№ҙе·ҰеҸіпјҢеӨ§ж•°жҚ®зҡ„жөӘжҪ®еҚ·иө·пјҢиҝҷдәӣдәүи®әиҝ…йҖҹиў«ж·№жІЎдәҶгҖӮзңӢи°·жӯҢи¶ӢеҠҝпјҢвҖқbigdataвҖқиҝҷдёӘиҜҚе°ұжҳҜйӮЈдёӘж—¶й—ҙдёҖдёӢеӯҗи№ҝеҚҮдәҶиө·жқҘгҖӮеҗ№йј“жүӢжңүеҮ 家пјҢдёҖ家жҳҜIDCпјҢжҜҸе№ҙз»ҷEMCеҒҡdigitaluniverseзҡ„жҠҘе‘ҠпјҢдёҠеҚҮеҲ°жіҪеӯ—иҠӮиҢғз•ҙ(з»ҷеӨ§е®¶дёӘжҰӮеҝөпјҢзҺ°еңЁзЎ¬зӣҳжҳҜеӨӘеӯ—иҠӮпјҢ1000еӨӘ=1жӢҚпјҢйҳҝйҮҢгҖҒFacebookзҡ„ж•°жҚ®жҳҜеҮ зҷҫжӢҚеӯ—иҠӮпјҢ1000жӢҚ=1иүҫпјҢзҷҫеәҰжҳҜдёӘдҪҚж•°иүҫеӯ—иҠӮпјҢи°·жӯҢжҳҜдёӨдҪҚж•°иүҫеӯ—иҠӮпјҢ1000иүҫ=1жіҪ);дёҖ家жҳҜйәҰиӮҜй”ЎпјҢеҸ‘еёғгҖҠеӨ§ж•°жҚ®пјҡеҲӣж–°гҖҒз«һдәүе’Ңз”ҹдә§еҠӣзҡ„дёӢдёҖдёӘеүҚжІҝгҖӢ;дёҖ家жҳҜгҖҠз»ҸжөҺеӯҰдәәгҖӢпјҢе…¶дёӯзҡ„йҮҚиҰҒеҶҷжүӢжҳҜи·ҹиҖҒиҲҚеҗҢи‘—гҖҠеӨ§ж•°жҚ®ж—¶д»ЈгҖӢзҡ„иӮҜе°јжҖқ?еә“е…ӢиҖ¶;иҝҳжңүдёҖ家жҳҜGartnerпјҢжқңж’°дәҶ3V(еӨ§гҖҒжқӮгҖҒеҝ«)пјҢе…¶е®һиҝҷ3VеңЁ2001е№ҙе°ұе·Із»Ҹиў«зј–еҮәжқҘдәҶпјҢеҸӘдёҚиҝҮеңЁеӨ§ж•°жҚ®иҜӯеўғйҮҢжңүдәҶе…Ёж–°зҡ„иҜ йҮҠгҖӮ
гҖҖгҖҖе’ұ们еӣҪеҶ…пјҢж¬ўжҖ»гҖҒеӣҪж ӢжҖ»д№ҹжҳҜеңЁ2011е№ҙе·ҰеҸіејҖе§Ӣе‘јеҗҒеҜ№еӨ§ж•°жҚ®зҡ„йҮҚи§ҶгҖӮ
гҖҖгҖҖ2012е№ҙеӯҗжІӣзҡ„д№ҰгҖҠеӨ§ж•°жҚ®гҖӢж•ҷиӮІж”ҝеәңе®ҳе‘ҳжңүеҠҹгҖӮиҖҒиҲҚе’Ңеә“е…ӢиҖ¶зҡ„гҖҠеӨ§ж•°жҚ®ж—¶д»ЈгҖӢжҸҗеҮәдәҶдёүеӨ§жҖқз»ҙпјҢзҺ°еңЁе·Із»Ҹиў«еҘүдёәеңӯиҮ¬пјҢдҪҶеҚғдёҮеҲ«еҪ“дҪңж”ҫд№Ӣеӣӣжө·иҖҢзҡҶеҮҶзҡ„зңҹзҗҶдәҶгҖӮ
гҖҖгҖҖжҜ”еҰӮиҰҒж•°жҚ®е…ЁйӣҶдёҚиҰҒйҮҮж ·гҖӮзҺ°е®һең°и®ІпјҢ1.жІЎжңүе…ЁйӣҶж•°жҚ®пјҢж•°жҚ®йғҪеңЁеӯӨеІӣйҮҢ;2.е…ЁйӣҶеӨӘиҙөпјҢйүҙдәҺеӨ§ж•°жҚ®дҝЎжҒҜеҜҶеәҰдҪҺпјҢжҳҜиҙ«зҹҝпјҢжҠ•е…Ҙдә§еҮәжҜ”дёҚи§Ғеҫ—еҘҪ;3.е®Ҹи§ӮеҲҶжһҗдёӯйҮҮж ·иҝҳжҳҜжңүз”Ёзҡ„пјҢзӣ–жҙӣжҷ®з”Ё5000дёӘж ·жң¬иғңиҝҮеҮ зҷҫдёҮи°ғжҹҘзҡ„еҒҡжі•иҝҳжҳҜжңүе®һи·өж„Ҹд№ү;4.йҮҮж ·иҰҒжңүйҡҸжңәжҖ§гҖҒд»ЈиЎЁжҖ§пјҢйҮҮи®ҝзҒ«иҪҰдёҠзҡ„ж°‘е·Ҙеҫ—еҮәйғҪд№°еҲ°зҘЁзҡ„з»“и®әдёҚжҳҜеҘҪйҮҮж ·пјҢзҺ°еңЁеҸӘеҒҡеӣәе®ҡз”өиҜқйҮҮж ·и°ғжҹҘд№ҹдёҚиЎҢдәҶ(移еҠЁз”өиҜқжҳҜеӨ§еӨҙ)пјҢеңЁеӣҪеӨ–еҹәдәҺTwitterйҮҮж ·д№ҹеҸ‘зҺ°дёҚе®Ңе…Ёе…·жңүд»ЈиЎЁжҖ§(иҖҒе№ҙдәәжІЎиў«еҢ…жӢ¬);5.йҮҮж ·зҡ„зјәзӮ№жҳҜжңүзҷҫеҲҶд№ӢеҮ зҡ„еҒҸе·®пјҢжӣҙдјҡдёўеӨұй»‘еӨ©й№…зҡ„дҝЎеҸ·пјҢеӣ жӯӨеңЁе…ЁйӣҶж•°жҚ®еӯҳеңЁдё”еҸҜеҲҶжһҗзҡ„еүҚжҸҗдёӢпјҢе…ЁйҮҸжҳҜйҰ–йҖүгҖӮе…ЁйҮҸ>еҘҪзҡ„йҮҮж ·>дёҚеқҮеҢҖзҡ„еӨ§йҮҸгҖӮ
гҖҖгҖҖеҶҚиҜҙж··жқӮжҖ§з”ұдәҺзІҫзЎ®жҖ§гҖӮжӢҘжҠұж··жқӮжҖ§(иҝҷж ·дёҖз§Қе®ўи§ӮзҺ°иұЎ)зҡ„жҖҒеәҰжҳҜдёҚй”ҷзҡ„пјҢдҪҶдёҚзӯүдәҺе–ңж¬ўж··жқӮжҖ§гҖӮж•°жҚ®жё…жҙ—жҜ”д»ҘеүҚжӣҙйҮҚиҰҒпјҢж•°жҚ®еӨұеҺ»иҫЁиҜҶеәҰгҖҒеӨұеҺ»жңүж•ҲжҖ§пјҢе°ұиҜҘжү”дәҶгҖӮиҖҒиҲҚеј•з”Ёи°·жӯҢPeterNovigзҡ„з»“и®әпјҢе°‘ж•°й«ҳиҙЁйҮҸж•°жҚ®+еӨҚжқӮз®—жі•иў«еӨ§йҮҸдҪҺиҙЁйҮҸж•°жҚ®+з®ҖеҚ•з®—жі•жү“иҙҘпјҢжқҘиҜҒжҳҺиҝҷдёҖжҖқз»ҙгҖӮPeterзҡ„з ”з©¶жҳҜWebж–Үжң¬еҲҶжһҗпјҢзЎ®е®һжҲҗз«ӢгҖӮдҪҶи°·жӯҢзҡ„ж·ұеәҰеӯҰд№ е·Із»ҸиҜҒжҳҺиҝҷдёӘдёҚе®Ңе…ЁеҜ№пјҢеҜ№дәҺдҝЎжҒҜз»ҙеәҰдё°еҜҢзҡ„иҜӯйҹігҖҒеӣҫзүҮж•°жҚ®пјҢйңҖиҰҒеӨ§йҮҸж•°жҚ®+еӨҚжқӮжЁЎеһӢгҖӮ
гҖҖгҖҖжңҖеҗҺжҳҜиҰҒзӣёе…іжҖ§дёҚиҰҒеӣ жһңжҖ§гҖӮеҜ№дәҺеӨ§жү№йҮҸзҡ„е°ҸеҶізӯ–пјҢзӣёе…іжҖ§жҳҜжңүз”Ёзҡ„пјҢеҰӮдәҡ马йҖҠзҡ„дёӘжҖ§еҢ–жҺЁиҚҗ;иҖҢеҜ№дәҺе°Ҹжү№йҮҸзҡ„еӨ§еҶізӯ–пјҢеӣ жһңжҖ§дҫқ然йҮҚиҰҒгҖӮе°ұеҰӮдёӯиҚҜпјҢеҸӘеҲ°иҫҫдәҶзӣёе…іжҖ§иҝҷдёҖжӯҘпјҢдҪҶе®ғжІЎжңүеҸҜи§ЈйҮҠжҖ§пјҢж— жі•еҫ—еҮәжҳҜжңүдәӣж ‘зҡ®е’Ңиҷ«еЈізҡ„еӣ еҜјиҮҙжІ»ж„Ҳзҡ„жһңгҖӮиҘҝиҚҜеңЁеҸ‘зҺ°зӣёе…іжҖ§еҗҺпјҢиҰҒеҒҡйҡҸжңәеҜ№з…§иҜ•йӘҢпјҢжҠҠжүҖжңүеҸҜиғҪеҜјиҮҙвҖңжІ»ж„Ҳзҡ„жһңвҖқзҡ„е№Іжү°еӣ зҙ жҺ’йҷӨпјҢиҺ·еҫ—еӣ жһңжҖ§е’ҢеҸҜи§ЈйҮҠжҖ§гҖӮеңЁе•ҶдёҡеҶізӯ–дёҠд№ҹжҳҜдёҖж ·пјҢзӣёе…іжҖ§еҸӘжҳҜејҖе§ӢпјҢе®ғеҸ–д»ЈдәҶжӢҚи„‘иўӢгҖҒзӣҙи§үиҺ·еҫ—зҡ„еҒҮи®ҫпјҢиҖҢеҗҺйқўйӘҢиҜҒеӣ жһңжҖ§зҡ„иҝҮзЁӢд»Қ然йҮҚиҰҒгҖӮ
гҖҖгҖҖжҠҠеӨ§ж•°жҚ®зҡ„дёҖдәӣеҲҶжһҗз»“жһңиҗҪе®һеңЁзӣёе…іжҖ§дёҠд№ҹжҳҜдјҰзҗҶзҡ„йңҖиҰҒпјҢеҠЁжңәдёҚд»ЈиЎЁиЎҢдёәгҖӮйў„жөӢжҖ§еҲҶжһҗд№ҹдёҖж ·пјҢдёҚ然иӯҰеҜҹдјҡйў„жөӢдәәзҠҜзҪӘпјҢдҝқйҷ©е…¬еҸёдјҡйў„жөӢдәәз”ҹз—…пјҢзӨҫдјҡеҫҲйә»зғҰгҖӮеӨ§ж•°жҚ®з®—жі•жһҒеӨ§еҪұе“ҚдәҶжҲ‘们зҡ„з”ҹжҙ»пјҢжңүж—¶еҖҷдјҡи§үеҫ—жҢәжӮІе“Җзҡ„пјҢжҳҜз®—жі•и§үеҫ—дәҶдҪ иҙ·дёҚиҙ·еҫ—еҲ°ж¬ҫпјҢи°·жӯҢжҜҸи°ғж•ҙдёҖж¬Ўз®—жі•пјҢеҫҲеӨҡеңЁзәҝе•Ҷдёҡе°ұдјҡеҸ—еҲ°еҪұе“ҚпјҢеӣ дёәиў«жҺ’еҲ°еҗҺйқўеҺ»дәҶгҖӮ
гҖҖгҖҖдёӢйқўж—¶й—ҙдёҚеӨҡдәҶпјҢе…ідәҺд»·еҖјз»ҙеәҰпјҢжҲ‘иҙҙдёҖдәӣд»ҘеүҚи®ІиҝҮзҡ„дёңиҘҝгҖӮеӨ§ж•°жҚ®жҖқжғідёӯеҫҲйҮҚиҰҒзҡ„дёҖзӮ№жҳҜеҶізӯ–жҷәиғҪеҢ–д№ӢеӨ–пјҢиҝҳжңүж•°жҚ®жң¬иә«зҡ„д»·еҖјеҢ–гҖӮиҝҷдёҖзӮ№дёҚиөҳиҝ°дәҶпјҢ引用马дә‘зҡ„иҜқеҗ§пјҢвҖңдҝЎжҒҜзҡ„еҮәеҸ‘зӮ№жҳҜжҲ‘и®ӨдёәжҲ‘жҜ”еҲ«дәәиҒӘжҳҺпјҢж•°жҚ®зҡ„еҮәеҸ‘зӮ№жҳҜи®ӨдёәеҲ«дәәжҜ”жҲ‘иҒӘжҳҺ;дҝЎжҒҜжҳҜдҪ жӢҝеҲ°ж•°жҚ®зј–иҫ‘д»ҘеҗҺз»ҷеҲ«дәәпјҢиҖҢж•°жҚ®жҳҜдҪ жҗңйӣҶж•°жҚ®д»ҘеҗҺдәӨз»ҷжҜ”дҪ жӣҙиҒӘжҳҺзҡ„дәәеҺ»еӨ„зҗҶгҖӮвҖқеӨ§ж•°жҚ®иғҪеҒҡд»Җд№Ҳ?д»·еҖјиҝҷдёӘVжҖҺд№Ҳжҳ е°„еҲ°е…¶д»–3Vе’Ңж—¶з©әиұЎйҷҗдёӯ?жҲ‘з”»дәҶдёӘеӣҫпјҡ
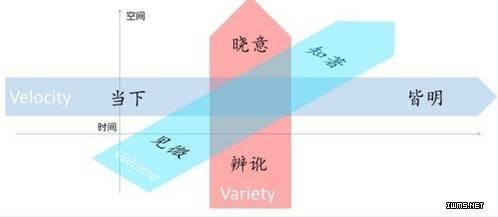
гҖҖгҖҖеҶҚиҙҙдёҠи§ЈйҮҠгҖӮвҖңи§Ғеҫ®вҖқдёҺвҖңзҹҘи‘—вҖқеңЁVolumeзҡ„з©әй—ҙз»ҙеәҰгҖӮе°Ҹж•°жҚ®и§Ғеҫ®пјҢдҪңдёӘдәәеҲ»з”»пјҢжҲ‘жӣҫз”ЁгҖҠдёҖд»Је®—еёҲгҖӢдёӯвҖңи§ҒиҮӘе·ұвҖқеҪўе®№д№Ӣ;еӨ§ж•°жҚ®зҹҘи‘—пјҢеҸҚжҳ иҮӘ然е’ҢзҫӨдҪ“зҡ„зү№еҫҒе’Ңи¶ӢеҠҝпјҢжҲ‘д»ҘвҖңи§ҒеӨ©ең°гҖҒи§Ғдј—з”ҹвҖқжҜ”е–»д№ӢгҖӮвҖңи‘—вҖқжҺЁеҠЁвҖңеҫ®вҖқ(еҰӮжҠҠдәәзҫӨз»ҶеҲҶдёәbuckets)пјҢеҸҲжӢүеҠЁвҖңеҫ®вҖқ(еҰӮжҺЁиҚҗзӣёдјјдәәзҫӨзҡ„еҒҸеҘҪз»ҷдёӘдәә)гҖӮвҖңеҫ®вҖқдёҺвҖңи‘—вҖқеҸҲеҸҚжҳ дәҶж—¶й—ҙз»ҙеәҰпјҢж•°жҚ®еҲҡдә§з”ҹж—¶дёӘдәәд»·еҖјжңҖеӨ§пјҢйҡҸзқҖж—¶й—ҙdecayжңҖеҗҺйҖҖеҢ–дёәд»ҘйӣҶеҗҲд»·еҖјдёәдё»гҖӮ
гҖҖгҖҖвҖңеҪ“дёӢвҖқе’ҢвҖңзҡҶжҳҺвҖқеңЁVelocityзҡ„ж—¶й—ҙз»ҙеәҰгҖӮеҪ“дёӢеңЁж—¶й—ҙеҺҹзӮ№пјҢжҳҜй—Әеҝөд№Ӣй—ҙзҡ„е®һж—¶жҷәж…§пјҢз»“еҗҲиҝҮеҫҖ(иҙҹиҪҙ)гҖҒйў„жөӢжңӘжқҘ(жӯЈиҪҙ)пјҢеҸҜд»ҘзҡҶжҳҺпјҢеҚіиҺ·еҫ—perpetualжҷәж…§гҖӮгҖҠиҘҝжёёи®°гҖӢйҮҢеҪўе®№зңҹеҒҮеӯҷжӮҹз©әпјҢдёҖдёӘжҳҜвҖңзҹҘеӨ©ж—¶гҖҒйҖҡеҸҳеҢ–вҖқпјҢдёҖдёӘжҳҜвҖңзҹҘеүҚеҗҺгҖҒдёҮзү©зҡҶжҳҺвҖқпјҢжӯЈеҘҪеҜ№еә”гҖӮдёәиҫҫеҲ°зҡҶжҳҺпјҢйңҖиҰҒе…ЁйҮҸеҲҶжһҗгҖҒйў„жөӢеҲҶжһҗе’ҢеӨ„ж–№ејҸеҲҶжһҗ(prescriptiveanalyticsпјҢдёәи®©и®ҫе®ҡзҡ„жңӘжқҘеҸ‘з”ҹпјҢйңҖиҰҒйҮҮеҸ–д»Җд№Ҳж ·зҡ„иЎҢеҠЁ)гҖӮ
гҖҖгҖҖвҖңиҫЁи®№вҖқе’ҢвҖңжҷ“ж„ҸвҖқеңЁVarietyзҡ„з©әй—ҙз»ҙеәҰгҖӮеҹәдәҺеӨ§дҪ“йҮҸгҖҒеӨҡжәҗејӮиҙЁзҡ„ж•°жҚ®пјҢиҫЁи®№иҝҮж»ӨеҷӘеЈ°гҖҒжҹҘжјҸиЎҘзјәгҖҒеҺ»дјӘеӯҳзңҹгҖӮжҷ“ж„ҸиҫҫеҲ°жӣҙй«ҳеўғз•ҢпјҢд»Һйқһз»“жһ„ж•°жҚ®дёӯжҸҗеҸ–иҜӯд№үгҖҒдҪҝжңәеҷЁиғҪеӨҹзӘҘжҺўдәәзҡ„жҖқжғіеўғз•ҢгҖҒиҫҫеҲ°иҝҮеҺ»з»“жһ„еҢ–ж•°жҚ®еҲҶжһҗдёҚиғҪиҫҫеҲ°д№Ӣй«ҳеәҰгҖӮ
гҖҖгҖҖе…ҲзңӢзҹҘи‘—пјҢеҜ№е®Ҹи§ӮзҺ°иұЎи§„еҫӢзҡ„з ”з©¶ж—©е·Іжңүд№ӢпјҢеӨ§ж•°жҚ®зҡ„зҹҘи‘—жңүдёӨдёӘж–°зү№зӮ№пјҢдёҖжҳҜд»ҺйҮҮж ·еҲ°е…ЁйҮҸпјҢжҜ”еҰӮеӨ®и§ҶеҺ»е№ҙвҖңдҪ е№ёзҰҸеҗ—вҖқзҡ„и°ғжҹҘпјҢжҳҜиЎ—еӨҙзҡ„йҮҮж ·пјҢеүҚдёҚд№…гҖҠдёӯеӣҪз»ҸжөҺз”ҹжҙ»еӨ§и°ғжҹҘгҖӢе…ідәҺе№ёзҰҸеҹҺеёӮжҺ’еҗҚзҡ„з»“и®әпјҢжҳҜеҹәдәҺ10дёҮд»Ҫй—®еҚ·(17дёӘй—®йўҳ)зҡ„йҮҮж ·пјҢиҖҢжё…еҚҺиЎҢдёәдёҺеӨ§ж•°жҚ®е®һйӘҢе®ӨеҒҡзҡ„е№ёзҰҸжҢҮж•°(继жҢәе…„гҖҒжҲ‘гҖҒиҝҳжңүеӨҡдҪҚжң¬зҫӨзҫӨеҸӢеҸӮдёҺ)пјҢжҳҜеҹәдәҺж–°жөӘеҫ®еҚҡж•°жҚ®зҡ„е…ЁйӣҶ(жүҳиҖҒзҺӢзҡ„зҰҸ)пјҢиҝҷдәӣж•°жҚ®жҳҜдәә们зҡ„иҮӘ然表иҫҫ(иҖҢдёҚжҳҜйқўеҜ№й—®еҚ·ж—¶зҡ„иў«еҠЁеә”еҜ№)пјҢеҗҢж—¶еҸҲжңүдёҠдёӢж–ҮиҜӯеўғпјҢеӣ жӯӨжӣҙзңҹе®һгҖҒд№ҹжӣҙжңүи§ЈйҮҠжҖ§гҖӮеҢ—дёҠе№ҝдёҚе№ёзҰҸпјҢжҳҜеӣ дёәз©әж°”иҝҳжҳҜжҲҝд»·жҲ–ж•ҷиӮІпјҢеңЁеҫ®еҚҡдёҠжӣҙе®№жҳ“дј ж’ӯзҡ„з§ҜжһҒжғ…з»ӘиҝҳжҳҜж¶ҲжһҒжғ…з»ӘпјҢж•°жҚ®е‘ҠиҜүдҪ зӯ”жЎҲгҖӮгҖҠдёӯеӣҪз»ҸжөҺз”ҹжҙ»еӨ§и°ғжҹҘгҖӢиҜҙвҖңеҶҚе°Ҹзҡ„еЈ°йҹіжҲ‘们йғҪеҗ¬еҫ—и§ҒвҖқпјҢжҳҜиҝҮеӨҙиҜқпјҢйҮҮж ·е’Ңдј з»ҹзҡ„з»ҹи®ЎеҲҶжһҗж–№жі•еҜ№ж•°жҚ®еҲҶеёғйҮҮз”ЁдёҖдәӣз®ҖеҢ–зҡ„жЁЎеһӢпјҢиҝҷдәӣжЁЎеһӢжҠҠејӮеёёе’Ңй•ҝе°ҫеҝҪз•ҘдәҶпјҢе…ЁйҮҸзҡ„еҲҶжһҗеҸҜд»ҘзңӢеҲ°й»‘еӨ©й№…зҡ„иә«еҪұпјҢеҗ¬еҲ°й•ҝе°ҫзҡ„еЈ°йҹігҖӮ
гҖҖгҖҖеҸҰдёҖдёӘзү№зӮ№жҳҜд»Һе®ҡжҖ§еҲ°е®ҡйҮҸгҖӮи®Ўз®—зӨҫдјҡеӯҰе°ұжҳҜжҠҠе®ҡйҮҸеҲҶжһҗеә”з”ЁеҲ°зӨҫдјҡеӯҰпјҢе·Із»ҸжңүдёҖжү№ж•°еӯҰ家гҖҒзү©зҗҶеӯҰ家жҲҗдәҶз»ҸжөҺеӯҰ家гҖҒе®Ҫе®ўпјҢзҺ°еңЁд»–们д№ҹеҸҜд»ҘйҖүжӢ©жҲҗдёәзӨҫдјҡеӯҰ家гҖӮеӣҪжі°еҗӣе®ү3IжҢҮж•°д№ҹжҳҜдёҖдёӘдҫӢеӯҗпјҢе®ғйҖҡиҝҮеҮ еҚҒдёҮз”ЁжҲ·зҡ„ж•°жҚ®пјҢдё»иҰҒжҳҜеҸҚжҳ жҠ•иө„жҙ»и·ғзЁӢеәҰе’ҢжҠ•иө„收зӣҠж°ҙе№ізҡ„жҢҮж ҮпјҢе»әз«ӢдёҖдёӘйҮҸеҢ–жЁЎеһӢжқҘжҺЁзҹҘж•ҙдҪ“жҠ•иө„жҷҜж°”еәҰгҖӮ
гҖҖгҖҖеҶҚзңӢи§Ғеҫ®пјҢжҲ‘и®ӨдёәеӨ§ж•°жҚ®зҡ„зңҹжӯЈе·®ејӮеҢ–дјҳеҠҝеңЁеҫ®и§ӮгҖӮиҮӘ然科еӯҰжҳҜе…Ҳе®Ҹи§ӮгҖҒе…·дҪ“пјҢиҝӣе…ҘеҲ°еҫ®и§Ӯе’ҢжҠҪиұЎпјҢиҝҷж—¶еӨ§ж•°жҚ®е°ұеҫҲйҮҚиҰҒдәҶгҖӮжҲ‘们жӣҙе…іжіЁзӨҫдјҡ科еӯҰпјҢйӮЈжҳҜе…Ҳеҫ®и§ӮгҖҒе…·дҪ“пјҢеҶҚе®Ҹи§ӮгҖҒжҠҪиұЎпјҢи®ёе°Ҹе№ҙзҙўжҖ§и®Өдёәе®Ҹи§Ӯз»ҸжөҺеӯҰжҳҜдјӘ科еӯҰгҖӮеҰӮжһңеёӮеңәжҳҜдёӘдҪ“иЎҢдёәзҡ„жҖ»е’ҢпјҢжҲ‘们еҺҹжқҘзңӢеҲ°жҳҜдёҖеј жҠҪиұЎжҙҫзҡ„з”»пјҢзңӢдёҚжҮӮпјҢйҖҡиҝҮе®ўжҲ·з»ҶеҲҶж…ўж…ўеҸҜд»ҘеҪўжҲҗдёҖеј еӨ§иҮҙзңӢеҫ—жҮӮзҡ„зҺ°е®һеӣҫжҷҜпјҢдёҚиҝҮжҳҜ马иөӣе…Ӣзҡ„пјҢеҶҚйҖҡиҝҮеҫ®еҲҶгҖҒз”ҡиҮіе®ҡдҪҚдёӘдәәпјҢеҪўжҲҗй«ҳжё…еӣҫгҖӮжҲ‘们жҜҸдёҖдёӘдәәзҺ°еңЁйғҪз”ҹжҙ»еңЁйӣ¶е”®е•Ҷзҡ„bucketдёӯ(еүҚйқўиҜҙзҡ„д№җиҙӯеҲӣйҖ дәҶиҝҷдёӘжҰӮеҝө)пјҢжңҖз®ҖеҚ•зҡ„жҳҜй«ҳ收е…ҘгҖҒдҪҺ收е…Ҙиҝҷзұ»еҸҚжҳ иғҢжҷҜзҡ„пјҢеҶҚжңүе°ұжҳҜеҸҚжҳ иЎҢдёәе’Ңз”ҹжҙ»ж–№ејҸзҡ„пјҢеҰӮвҖңзІҫжү“з»Ҷз®—вҖқгҖҒвҖңеҸій”®зӮ№еҮ»дёҖж—ҸвҖқ(дҪҝз”ЁеҸій”®зҡ„жҜ”иҫғtechsavvy)гҖӮеҸҚиҝҮжқҘжҲ‘们ж¶Ҳиҙ№иҖ…д№ҹеёҢжңӣиғҪеӨҹиҺ·еҫ—дёӘжҖ§еҢ–зҡ„е°ҠеҙҮпјҢNobodywantstobenobodytodayгҖӮ
гҖҖгҖҖдәҶ解并жҺҢжҸЎе®ўжҲ·жҜ”д»ҘеҫҖд»»дҪ•ж—¶еҖҷйғҪжӣҙйҮҚиҰҒгҖӮеҘҘе·ҙ马иөўеңЁеӨ§ж•°жҚ®дёҠпјҢе°ұжҳҜеӣ дёәд»–зҹҘйҒ“иҘҝеІё40-49еІҒеҘіжҖ§зҡ„з”·зҘһжҳҜд№”жІ»В·е…ӢйІҒе°јпјҢдёңеІёеҗҢж ·е№ҙйҫ„ж®өеҘіжҖ§зҡ„еҒ¶еғҸеҲҷжҳҜиҺҺжӢүВ·жқ°иҘҝеҚЎВ·её•е…Ӣ(гҖҠж¬ІжңӣйғҪеёӮгҖӢзҡ„дё»и§’)пјҢд»–иҝҳиҰҒжӣҙз»ҶеҲҶпјҢж‘Үж‘Ҷе·һжҜҸдёҖдёӘйғЎжҜҸдёҖдёӘе№ҙйҫ„ж®өжҜҸдёҖдёӘж—¶й—ҙж®өеңЁзңӢд»Җд№Ҳз”өи§ҶпјҢж‘Үж‘Ҷе·һ(дҝ„дәҘдҝ„)1%йҖүж°‘йҡҸж—¶й—ҙеҸҳеҢ–зҡ„жҠ•зҘЁеҖҫеҗ‘пјҢж‘Үж‘ҶйҖүж°‘еңЁRedditдёҠиҝҳжҳҜFacebookдёҠпјҢйғҪеңЁе…¶жҺҢжҸЎд№ӢдёӯгҖӮ
гҖҖгҖҖеҜ№дәҺдјҒдёҡжқҘиҜҙпјҢиҰҒд»Һд»Ҙдә§е“ҒдёәдёӯеҝғпјҢиҪ¬еҲ°д»Ҙе®ўжҲ·(д№°еҚ•иҖ…)з”ҡиҮіз”ЁжҲ·(дҪҝз”ЁиҖ…)дёәдёӯеҝғпјҢд»Һе…іжіЁз”ЁжҲ·иғҢжҷҜеҲ°е…іжіЁе…¶иЎҢдёәгҖҒж„Ҹеӣҫе’Ңж„Ҹеҗ‘пјҢд»Һе…іжіЁдәӨжҳ“еҪўжҲҗиҪ¬еҲ°е…іжіЁжҜҸдёҖдёӘдәӨдә’зӮ№/и§ҰзӮ№пјҢз”ЁжҲ·жҳҜд»Һд»Җд№Ҳи·Ҝеҫ„еҸ‘зҺ°жҲ‘зҡ„дә§е“Ғзҡ„пјҢеҶіе®ҡд№ӢеүҚеҸҲеҒҡдәҶд»Җд№ҲпјҢд№°дәҶд»ҘеҗҺеҸҲжңүд»Җд№ҲеҸҚйҰҲпјҢжҳҜйҖҡиҝҮзҪ‘йЎөгҖҒиҝҳжҳҜQQгҖҒеҫ®еҚҡжҲ–жҳҜеҫ®дҝЎгҖӮ
гҖҖгҖҖеҶҚ讲第дёүдёӘпјҢеҪ“дёӢгҖӮж—¶й—ҙжҳҜйҮ‘й’ұпјҢиӮЎзҘЁдәӨжҳ“е°ұжҳҜеҝ«йұјеҗғж…ўйұјпјҢз”Ёе…Қиҙ№иӮЎзҘЁдәӨжҳ“иҪҜ件жңүеҮ з§’зҡ„延иҝҹпјҢиҖҢеҚ зҫҺеӣҪдәӨжҳ“йҮҸ60-70%зҡ„й«ҳйў‘зЁӢеәҸеҢ–дәӨжҳ“еҲҷиҰҒеҸ‘зҺ°жҜ«з§’зә§гҖҒдҪҺиҮі1зҫҺеҲҶзҡ„дәӨжҳ“жңәдјҡгҖӮж—¶й—ҙеҸҲжҳҜз”ҹе‘ҪпјҢзҫҺеӣҪеӣҪ家еӨ§ж°”дёҺжө·жҙӢз®ЎзҗҶеұҖзҡ„и¶…зә§и®Ўз®—жңәеңЁж—Ҙжң¬311ең°йңҮеҗҺ9еҲҶй’ҹеҸ‘еҮәжө·е•ёйў„иӯҰпјҢе·Із»ҸеӨӘжҷҡгҖӮж—¶й—ҙиҝҳжҳҜжңәдјҡгҖӮзҺ°еңЁжүҖи°“зҡ„иҙӯзү©зҜ®еҲҶжһҗз”Ёзҡ„е…¶е®һ并дёҚжҳҜзңҹжӯЈзҡ„иҙӯзү©зҜ®пјҢиҖҢжҳҜз»“еёҗе®Ңзҡ„е°ҸзҘЁпјҢзңҹжӯЈжңүд»·еҖјзҡ„жҳҜеҪ“йЎҫе®ўиҝҳжӢҺзқҖиҙӯзү©зҜ®пјҢеңЁжөҸи§ҲгҖҒиҜ•з”ЁгҖҒйҖүжӢ©е•Ҷе“Ғзҡ„ж—¶еҖҷпјҢеңЁжҜҸдёҖдёӘи§ҰзӮ№еҪұе“Қд»–/еҘ№зҡ„йҖүжӢ©гҖӮж•°жҚ®д»·еҖје…·жңүеҚҠиЎ°жңҹпјҢжңҖж–°йІңзҡ„ж—¶еҖҷдёӘжҖ§еҢ–д»·еҖјжңҖеӨ§пјҢжёҗжёҗйҖҖеҢ–еҲ°еҸӘжңүйӣҶеҗҲд»·еҖјгҖӮеҪ“дёӢзҡ„жҷәж…§жҳҜд»ҺеҲ»иҲҹжұӮеү‘еҲ°и§Ғж—¶зҹҘеҮ пјҢеҺҹжқҘ10е№ҙдёҖж¬Ўзҡ„дәәеҸЈжҷ®жҹҘе°ұжҳҜеҲ»иҲҹжұӮеү‘пјҢиҖҢзҺ°еңЁдёңиҺһдёҖеҮәдәӢзҷҫеәҰиҝҒеҫҷеӣҫе°ұеҸҚжҳ еҮәжқҘдәҶгҖӮеҪ“然пјҢеҪ“дёӢ并дёҚдёҖе®ҡжҳҜе®Ңе…ЁеҮҶзЎ®зҡ„пјҢе…¶е®һеҰӮжһңжІЎжңүжӣҙеӨҡгҖҒжӣҙд№…зҡ„ж•°жҚ®пјҢеҢҶеҝҷеҜ№зҷҫеәҰиҝҒеҫҷеӣҫи§ЈиҜ»жҳҜеҸҜиғҪйҷ·е…ҘиҜҜеҢәзҡ„гҖӮ
гҖҖгҖҖ第еӣӣдёӘпјҢзҡҶжҳҺгҖӮж—¶й—ҙжңүйҷҗпјҢе°ұз®ҖеҚ•иҜҙдәҶгҖӮе°ұжҳҜд»Һж”ҫ马еҗҺзӮ®еҲ°ж–ҷдәӢеҰӮзҘһ(predictiveanalytics)пјҢд»Һж–ҷдәӢеҰӮзҘһеҲ°иҝҗзӯ№её·е№„(prescriptiveanalytics)пјҢеҸӘзҹҘйҒ“жңүдёңйЈҺжҳҜйў„жөӢеҲҶжһҗпјҢзЎ®е®ҡиҰҒеҖҹз®ӯзҡ„зӣ®ж ҮгҖҒ并з»ҷеҮәеӨ„ж–№еҲ©з”ЁиҚүиҲ№жқҘеҖҹпјҢе°ұжҳҜеӨ„ж–№жҖ§еҲҶжһҗгҖӮжҲ‘们зҺ°еңЁиҰҒжҸҗй«ҳе“Қеә”еәҰгҖҒйҷҚдҪҺжөҒеӨұзҺҮгҖҒеҗёеј•ж–°е®ўжҲ·пјҢйңҖиҰҒеӨ„ж–№жҖ§еҲҶжһҗгҖӮ
гҖҖгҖҖиҫЁи®№е°ұжҳҜеҲ©з”ЁеӨҡжәҗж•°жҚ®иҝҮж»ӨеҷӘеЈ°гҖҒжҹҘжјҸиЎҘзјәе’ҢеҺ»дјӘеӯҳзңҹгҖӮ20еӨҡдёӘзңҒеёӮзҡ„GDPд№Ӣе’Ңи¶…иҝҮе…ЁеӣҪзҡ„GDPе°ұжҳҜдёҖдёӘдҫӢеӯҗпјҢжҲ‘们зҡ„GPSжңүеҮ еҚҒзұізҡ„иҜҜе·®пјҢдҪҶдёҺең°еӣҫж•°жҚ®з»“еҗҲе°ұиғҪеҒҡеҲ°зІҫзЎ®пјҢGPSеңЁеҹҺеёӮзҡ„й«ҳжҘјдёӯжІЎжңүдҝЎеҸ·пјҢеҸҜд»ҘдёҺжғҜжҖ§еҜјиҲӘз»“еҗҲгҖӮ
гҖҖгҖҖжҷ“ж„Ҹж¶үеҸҠеҲ°еӨ§ж•°жҚ®дёӢзҡ„жңәеҷЁжҷәиғҪпјҢжҳҜдёӘеӨ§й—®йўҳпјҢд№ҹдёҚеұ•ејҖдәҶгҖӮиҙҙдёҖж®өжҲ‘зҡ„ж–Үз« пјҡжңүдәәиҜҙеңЁж¶үеҸҠвҖңжҷ“ж„ҸвҖқзҡ„йўҶеҹҹдәәжҳҜж— жі•жӣҝд»Јзҡ„гҖӮиҝҷеңЁеүҚеӨ§ж•°жҚ®ж—¶д»ЈжҳҜдәӢе®һгҖӮгҖҠзӮ№зҗғжҲҗйҮ‘(Moneyball)гҖӢи®Ізҡ„жҳҜж•°йҮҸеҢ–еҲҶжһҗе’Ңйў„жөӢеҜ№жЈ’зҗғиҝҗеҠЁзҡ„иҙЎзҢ®пјҢе®ғеңЁеӨ§ж•°жҚ®иғҢжҷҜдёӢеҮәзҺ°дәҶдј ж’ӯзҡ„иҜҜеҢәпјҡдёҖгҖҒе®ғе…¶е®һдёҚжҳҜеӨ§ж•°жҚ®пјҢиҖҢжҳҜж—©е·ІеӯҳеңЁзҡ„ж•°жҚ®жҖқз»ҙе’Ңж–№жі•;дәҢгҖҒе®ғеҲ»ж„ҸжҲ–ж— ж„ҸеҝҪз•ҘдәҶзҗғжҺўзҡ„дҪңз”ЁгҖӮд»ҺиҜ»иҖ…зңӢжқҘпјҢеҘҘе…Ӣе…°з«һжҠҖйҳҹзҡ„жҖ»з»ҸзҗҶжҜ”еҲ©В·жҜ”жҒ©з”Ёж•°йҮҸеҢ–еҲҶжһҗеҸ–д»ЈдәҶзҗғжҺўгҖӮиҖҢдәӢе®һжҳҜпјҢеңЁиҝҗз”Ёж•°йҮҸеҢ–е·Ҙе…·зҡ„еҗҢж—¶пјҢжҜ”жҒ©д№ҹеўһеҠ дәҶзҗғжҺўзҡ„иҙ№з”ЁпјҢеҶӣеҠҹз« йҮҢжңүжңәеҷЁзҡ„дёҖеҚҠпјҢд№ҹжңүдәәзҡ„дёҖеҚҠпјҢеӣ дёәзҗғжҺўеҜ№иҝҗеҠЁе‘ҳе®ҡжҖ§жҢҮж Ү(еҰӮз«һдәүжҖ§гҖҒжҠ—еҺӢеҠӣгҖҒж„Ҹеҝ—еҠӣзӯү)зҡ„иЎЎйҮҸжҳҜе°‘ж•°з»“жһ„еҢ–йҮҸеҢ–жҢҮж Үж— жі•еҲ»з”»зҡ„гҖӮеӨ§ж•°жҚ®ж”№еҸҳдәҶиҝҷдёҖеҲҮгҖӮдәәзҡ„ж•°еӯ—и¶іиҝ№зҡ„ж— ж„ҸиҜҶи®°еҪ•пјҢд»ҘеҸҠжңәеҷЁеӯҰд№ (е°Өе…¶жҳҜж·ұеәҰеӯҰд№ )жҷ“ж„ҸиғҪеҠӣзҡ„еўһејәпјҢеҸҜиғҪйҖҗжёҗж”№еҸҳжңәеҷЁзҡ„еҠЈеҠҝгҖӮд»Ҡе№ҙжҲ‘们зңӢеҲ°еҹәдәҺеӨ§ж•°жҚ®зҡ„жғ…ж„ҹеҲҶжһҗгҖҒд»·еҖји§ӮеҲҶжһҗе’ҢдёӘдәәеҲ»з”»пјҢеҪ“иҝҷдәӣеә”з”ЁдәҺдәәеҠӣиө„жәҗпјҢе·Із»ҸжҲ–еӨҡжҲ–е°‘дҪ“зҺ°дәҶзҗғжҺўжүҝжӢ…зҡ„гҖӮ
еЈ°жҳҺ: жң¬ж–Үз”ұ( зҲұиҜҙдә‘зҪ‘ )еҺҹеҲӣзј–иҜ‘пјҢиҪ¬иҪҪиҜ·дҝқз•ҷй“ҫжҺҘ: иҜҰи§ЈеӨ§ж•°жҚ®зҡ„жҖқжғіеҪўжҲҗдёҺд»·еҖјз»ҙеәҰ
- дёҠдёҖзҜҮпјҡеҲ—дёҫдёҚйҖӮеҗҲеӨ§ж•°жҚ®еӨ„зҗҶзҡ„10件дәӢжғ…-
- дёӢдёҖзҜҮпјҡзҺ©иҪ¬еӨ§ж•°жҚ®пјҡйңҖиҰҒзҹҘжҷ“зҡ„12з§Қе·Ҙе…·
иҜҰи§ЈеӨ§ж•°жҚ®зҡ„жҖқжғіеҪўжҲҗдёҺд»·еҖјз»ҙеәҰпјҡзӯүжӮЁеқҗжІҷеҸ‘е‘ўпјҒ
еҸ‘иЎЁиҜ„и®ә
- й«ҳеҸҜз”ЁдёҺиҙҹиҪҪеқҮиЎЎзҡ„еҢәеҲ«
- lampжһ¶жһ„еёҲеҝ…зңӢз»Ҹе…ё
- еӯҳеӮЁжһҒе®ў | еҶҚдёҚжӢҘжҠұDockerе®№еҷЁпјҢдҪ зҡ„...
- е®һж–ҪеҲӣж–°й©ұеҠЁеҸ‘еұ•жҲҳз•ҘпјҢжҺЁеҠЁдјҒдёҡеҸ‘еұ•
- еӨ§ж•°жҚ®е…Ҙдҫөйҡҗз§Ғпјҡиў«еҚ–иҝҳдёҚз®—пјҢй’ұиўӢд№ҹиў«...
- дёәд»Җд№ҲеҫҲеӨҡSaaSдјҒдёҡзә§дә§е“ҒйғҪзҶ¬дёҚиҝҮ第...
- дәҡ马йҖҠдә‘и®Ўз®—дёӯеҝғдёәдҪ•зңӢдёҠе®ҒеӨҸдёӯеҚ«пјҹ
- еҰӮдҪ•зІҫеҝғи®ҫи®ЎCDNжһ¶жһ„пјҹ
- Linuxиҝҗз»ҙпјҡзҺ°зҠ¶гҖҒе…Ҙй—Ёе’ҢжңӘжқҘд№Ӣи·Ҝ
- shellи„ҡжң¬дёӯдёҖдәӣзү№ж®Ҡз¬ҰеҸ·
- дҪҝз”ЁVirtualBoxжһ„е»әCloudStackжөӢиҜ•...
- жһ„е»әејҖжәҗз§Ғжңүдә‘еҲ©ејҠеҲҶжһҗ
- и§ЈиҜ»дёүеӨ§ж•°жҚ®дёӯеҝғзҪ‘з»ңжҠҖжңҜпјҡдёәдә‘и®Ўз®—иҖҢ...
- Googleж•ҙеҗҲStackDriverжҠҖжңҜпјҡеҗ‘ејҖеҸ‘...
- зӣҳзӮ№ж•°жҚ®еә“2014пјҡдёҖжӯҘд№ӢйҒҘеҲ°дә‘з«Ҝ
- еӨ§иҜқзҷҪиҜқдә‘и®Ўз®—
- д»Һдә‘зҡ„иө·жәҗжө…жһҗеӣҪеҶ…дә‘е№іеҸ°зҡ„зҺ°зҠ¶е’ҢжңӘжқҘ
- Windows Azureе…¬жңүдә‘зӣҙж’ӯдё–з•ҢжқҜ
- еӨ®и§ҶжҗәйҳҝйҮҢдә‘и®Ўз®—жү“йҖ е…ЁзҪ‘жңҖеҝ«дё–з•ҢжқҜзӣҙ...
- дёәдә‘иҖҢеҸҳ Office 365еј•йўҶзҡ„е…ЁйқўиҪ¬еһӢ
- иҷҡжӢҹеҢ–е№іеҸ°cloudstack
- дә‘и®Ўз®—дҝЎжҒҜеҢ–е»әи®ҫеңЁдёӯе°ҸдјҒдёҡеә”з”Ёзҡ„еҮ з§Қ...
- AWSе®үе…Ёи§ЈеҶіж–№жЎҲиҗҪең°дёӯеӣҪ жө…жһҗдә‘е®үе…Ё...
- ITжңҚеҠЎз®ЎзҗҶиҝҲе…Ҙдә‘ж•ҙеҗҲж—¶д»Ј
- lampжһ¶жһ„еёҲеҝ…зңӢз»Ҹе…ё
- 12еӨ§зј–зЁӢиҜӯиЁҖ收е…ҘжҺ’иЎҢжҰң-жҠҖжңҜеҚҡе®ў-@еӨ§ж•°...
- йҳҝйҮҢдә‘и®Ўз®—жҺЁе…Ёж–°еӨ§ж•°жҚ®е·Ҙе…·вҖңйҮҮдә‘й—ҙвҖқ
- еҲҶеёғејҸи®Ўз®—гҖҒ并иЎҢи®Ўз®—еҸҠйӣҶзҫӨгҖҒзҪ‘ж јгҖҒдә‘...
- еӨ§ж•°жҚ®ж—¶д»ЈеӨ§ж•°жҚ®еҲҶжһҗзҡ„е“ІеӯҰеҸҳйқ©
- зҪ‘з»ңжҲҗжң¬иҶЁиғҖеўһеҠ е…¬жңүдә‘иҙҰеҚ•
зғӯй—Ёж Үзӯҫ
- AWS Docker EC2 дә‘еӯҳеӮЁ дә‘е®үе…Ё дә‘еә”з”Ё дә‘и®Ўз®— дә‘и®Ўз®—дёҺдҝЎжҒҜеҢ– дә‘и®Ўз®—дёҺеӨ§ж•°жҚ® дә‘и®Ўз®—дёҺзү©иҒ”зҪ‘ дә‘и®Ўз®—е№іеҸ° дә‘и®Ўз®—еә”з”Ё дә‘и®Ўз®—еә”з”Ёе®һдҫӢ дә‘и®Ўз®—еә”з”ЁйўҶеҹҹ дә‘и®Ўз®—жҠҖжңҜ дә‘и®Ўз®—жҳҜд»Җд№Ҳ дә‘и®Ўз®—жҳҜд»Җд№Ҳж„ҸжҖқ дә‘и®Ўз®—зҪ‘ дә’иҒ”зҪ‘йҮ‘иһҚ дҝЎжҒҜеҢ– еӨ§ж•°жҚ® еӨ§ж•°жҚ® еӨ§ж•°жҚ®еҲҶжһҗ еӨ§ж•°жҚ®ж—¶д»Ј е№ҝе·һдә‘и®Ўз®—зҪ‘ зү©иҒ”зҪ‘ зңҹеҘҪдә‘и®Ўз®—зҪ‘ 移еҠЁдә’иҒ”зҪ‘ йҳҝйҮҢдә‘ йҳҝйҮҢдә‘и®Ўз®—