и°·жӯҢжҠҖжңҜ”дёүе®қ”д№ӢBigTable — еӨ§ж•°жҚ®дә‘и®Ўз®—ж—¶д»Ј
ж—¶й—ҙ:14-12-25 ж Ҹзӣ®:Google, еӨ§ж•°жҚ® дҪңиҖ…:зҲұиҜҙдә‘зҪ‘ иҜ„и®ә:0 зӮ№еҮ»: 2,056 ж¬Ў
жң¬ж–Үж Үзӯҫпјҡ BigTable , дә‘и®Ўз®— , еӨ§ж•°жҚ® , и°·жӯҢдёүе®қ
2006е№ҙзҡ„OSDIжңүдёӨзҜҮgoogleзҡ„и®әж–ҮпјҢеҲҶеҲ« жҳҜBigTableе’ҢChubbyгҖӮChubbyжҳҜдёҖдёӘеҲҶеёғејҸй”ҒжңҚеҠЎпјҢеҹәдәҺPaxosз®—жі•пјӣBigTableжҳҜдёҖдёӘз”ЁдәҺз®ЎзҗҶз»“жһ„еҢ–ж•°жҚ®зҡ„еҲҶеёғејҸеӯҳеӮЁзі»з»ҹпјҢ жһ„е»әеңЁGFSгҖҒChubbyгҖҒSSTableзӯүgoogleжҠҖжңҜд№ӢдёҠгҖӮзӣёеҪ“еӨҡзҡ„googleеә”з”ЁдҪҝз”ЁдәҶBigTableпјҢжҜ”еҰӮGoogle Earthе’ҢGoogle AnalyticsпјҢеӣ жӯӨе®ғе’ҢGFSгҖҒMapReduce并称дёәи°·жӯҢжҠҖжңҜ"дёүе®қ"гҖӮ
дёҺGFSе’ҢMapReduceзҡ„и®әж–ҮзӣёжҜ”пјҢжҲ‘и§үеҫ—BigTableзҡ„и®әж–ҮйҡҫжҮӮдёҖдәӣгҖӮдёҖж–№йқўжҳҜеӣ дёәиҮӘе·ұеҜ№ж•°жҚ®еә“дёҚеӨӘдәҶи§ЈпјҢеҸҰдёҖж–№йқўеҸҲжҳҜеӣ дёәеҜ№ж•°жҚ®еә“зҡ„зҗҶи§ЈеұҖйҷҗдәҺе…ізі»еһӢж•°жҚ®еә“гҖӮе°қиҜ•з”Ёе…ізі»еһӢж•°жҚ®жЁЎеһӢеҺ»зҗҶи§ЈBigTableе°ұе®№жҳ“"иө°зҒ«е…Ҙйӯ”"гҖӮеңЁиҝҷйҮҢжҺЁиҚҗдёҖзҜҮж–Үз« пјҡUnderstanding HBase and BigTableпјҢзӣёдҝЎиҝҷзҜҮж–Үз« еҜ№зҗҶи§ЈBigTable/HBaseзҡ„ж•°жҚ®жЁЎеһӢжңүеҫҲеӨ§её®еҠ©гҖӮ
1 д»Җд№ҲжҳҜBigTable
Bigtable жҳҜдёҖдёӘдёәз®ЎзҗҶеӨ§и§„жЁЎз»“жһ„еҢ–ж•°жҚ®иҖҢи®ҫи®Ўзҡ„еҲҶеёғејҸеӯҳеӮЁзі»з»ҹпјҢеҸҜд»Ҙжү©еұ•еҲ°PBзә§ж•°жҚ®е’ҢдёҠеҚғеҸ°жңҚеҠЎеҷЁгҖӮеҫҲеӨҡgoogleзҡ„йЎ№зӣ®дҪҝз”ЁBigtableеӯҳеӮЁж•°жҚ®пјҢиҝҷдәӣ еә”з”ЁеҜ№BigtableжҸҗеҮәдәҶдёҚеҗҢзҡ„жҢ‘жҲҳпјҢжҜ”еҰӮж•°жҚ®и§„жЁЎзҡ„иҰҒжұӮгҖҒ延иҝҹзҡ„иҰҒжұӮгҖӮBigtableиғҪж»Ўи¶іиҝҷдәӣеӨҡеҸҳзҡ„иҰҒжұӮпјҢдёәиҝҷдәӣдә§е“ҒжҲҗеҠҹең°жҸҗдҫӣдәҶзҒөжҙ»гҖҒй«ҳжҖ§иғҪ зҡ„еӯҳеӮЁи§ЈеҶіж–№жЎҲгҖӮ
BigtableзңӢиө·жқҘеғҸдёҖдёӘж•°жҚ®еә“пјҢйҮҮз”ЁдәҶеҫҲеӨҡж•°жҚ® еә“зҡ„е®һзҺ°зӯ–з•ҘгҖӮдҪҶжҳҜBigtable并дёҚж”ҜжҢҒе®Ңж•ҙзҡ„е…ізі»еһӢж•°жҚ®жЁЎеһӢпјӣиҖҢжҳҜдёәе®ўжҲ·з«ҜжҸҗдҫӣдәҶдёҖз§Қз®ҖеҚ•зҡ„ж•°жҚ®жЁЎеһӢпјҢе®ўжҲ·з«ҜеҸҜд»ҘеҠЁжҖҒең°жҺ§еҲ¶ж•°жҚ®зҡ„еёғеұҖе’Ңж јејҸпјҢ并且 еҲ©з”Ёеә•еұӮж•°жҚ®еӯҳеӮЁзҡ„еұҖйғЁжҖ§зү№еҫҒгҖӮBigtableе°Ҷж•°жҚ®з»ҹз»ҹзңӢжҲҗж— ж„Ҹд№үзҡ„еӯ—иҠӮдёІпјҢе®ўжҲ·з«ҜйңҖиҰҒе°Ҷз»“жһ„еҢ–е’Ңйқһз»“жһ„еҢ–ж•°жҚ®дёІиЎҢеҢ–еҶҚеӯҳе…ҘBigtableгҖӮ
дёӢж–ҮеҜ№BigTableзҡ„ж•°жҚ®жЁЎеһӢе’Ңеҹәжң¬е·ҘдҪңеҺҹзҗҶиҝӣиЎҢд»Ӣз»ҚпјҢиҖҢеҗ„з§ҚдјҳеҢ–жҠҖжңҜпјҲеҰӮеҺӢзј©гҖҒBloom FilterзӯүпјүдёҚеңЁи®Ёи®әиҢғеӣҙгҖӮ
2 BigTableзҡ„ж•°жҚ®жЁЎеһӢ
BigtableдёҚжҳҜе…ізі»еһӢж•°жҚ®еә“пјҢдҪҶжҳҜеҚҙжІҝз”ЁдәҶеҫҲеӨҡе…ізі»еһӢж•°жҚ®еә“зҡ„жңҜиҜӯпјҢеғҸtableпјҲиЎЁпјүгҖҒrowпјҲиЎҢпјүгҖҒcolumnпјҲеҲ—пјүзӯүгҖӮиҝҷе®№жҳ“и®©иҜ»иҖ…иҜҜе…Ҙжӯ§йҖ”пјҢе°Ҷе…¶дёҺе…ізі»еһӢж•°жҚ®еә“зҡ„жҰӮеҝөеҜ№еә”иө·жқҘпјҢд»ҺиҖҢйҡҫд»ҘзҗҶи§Ји®әж–ҮгҖӮUnderstanding HBase and BigTableжҳҜзҜҮеҫҲдјҳз§Җзҡ„ж–Үз« пјҢеҸҜд»Ҙеё®еҠ©иҜ»иҖ…д»Һе…ізі»еһӢж•°жҚ®жЁЎеһӢзҡ„жҖқз»ҙе®ҡеҠҝдёӯиө°еҮәжқҘгҖӮ
жң¬иҙЁдёҠиҜҙпјҢBigtableжҳҜдёҖдёӘй”®еҖјпјҲkey-valueпјүжҳ е°„гҖӮжҢүдҪңиҖ…зҡ„иҜҙжі•пјҢBigtableжҳҜдёҖдёӘзЁҖз–Ҹзҡ„пјҢеҲҶеёғејҸзҡ„пјҢжҢҒд№…еҢ–зҡ„пјҢеӨҡз»ҙзҡ„жҺ’еәҸжҳ е°„гҖӮ
е…ҲжқҘзңӢзңӢеӨҡз»ҙгҖҒжҺ’еәҸгҖҒжҳ е°„гҖӮBigtableзҡ„й”®жңүдёүз»ҙпјҢеҲҶеҲ«жҳҜиЎҢй”®пјҲrow keyпјүгҖҒеҲ—й”®пјҲcolumn keyпјүе’Ңж—¶й—ҙжҲіпјҲtimestampпјүпјҢиЎҢй”®е’ҢеҲ—й”®йғҪжҳҜеӯ—иҠӮдёІпјҢж—¶й—ҙжҲіжҳҜ64дҪҚж•ҙеһӢпјӣиҖҢеҖјжҳҜдёҖдёӘеӯ—иҠӮдёІгҖӮеҸҜд»Ҙз”ЁВ (row:string, column:string, time:int64)вҶ’stringВ жқҘиЎЁзӨәдёҖжқЎй”®еҖјеҜ№и®°еҪ•гҖӮ
иЎҢй”®еҸҜд»ҘжҳҜд»»ж„Ҹеӯ—иҠӮдёІпјҢйҖҡеёёжңү10-100еӯ—иҠӮгҖӮиЎҢзҡ„иҜ»еҶҷйғҪжҳҜеҺҹеӯҗжҖ§зҡ„гҖӮBigtableжҢүз…§иЎҢй”®зҡ„еӯ—е…ёеәҸеӯҳеӮЁж•°жҚ®гҖӮBigtableзҡ„иЎЁдјҡж №жҚ®иЎҢй”®иҮӘеҠЁеҲ’еҲҶдёәзүҮпјҲtabletпјүпјҢзүҮжҳҜиҙҹиҪҪеқҮиЎЎзҡ„еҚ•е…ғгҖӮжңҖеҲқиЎЁйғҪеҸӘжңүдёҖдёӘзүҮпјҢдҪҶйҡҸзқҖиЎЁдёҚж–ӯеўһеӨ§пјҢзүҮдјҡиҮӘеҠЁеҲҶиЈӮпјҢзүҮзҡ„еӨ§е°ҸжҺ§еҲ¶еңЁ100-200MBгҖӮиЎҢжҳҜиЎЁзҡ„第дёҖзә§зҙўеј•пјҢжҲ‘们еҸҜд»ҘжҠҠиҜҘиЎҢзҡ„еҲ—гҖҒж—¶й—ҙе’ҢеҖјзңӢжҲҗдёҖдёӘж•ҙдҪ“пјҢз®ҖеҢ–дёәдёҖз»ҙй”®еҖјжҳ е°„пјҢзұ»дјјдәҺпјҡ
- table{В В
- В В "1"В :В {sth.},//дёҖиЎҢВ В
- В В "aaaaa"В :В {sth.},В В
- В В "aaaab"В :В {sth.},В В
- В В "xyz"В :В {sth.},В В
- В В "zzzzz"В :В {sth.}В В
- }В В
еҲ— жҳҜ第дәҢзә§зҙўеј•пјҢжҜҸиЎҢжӢҘжңүзҡ„еҲ—жҳҜдёҚеҸ—йҷҗеҲ¶зҡ„пјҢеҸҜд»ҘйҡҸж—¶еўһеҠ еҮҸе°‘гҖӮдёәдәҶж–№дҫҝз®ЎзҗҶпјҢеҲ—иў«еҲҶдёәеӨҡдёӘеҲ—ж—ҸпјҲcolumn familyпјҢжҳҜи®ҝй—®жҺ§еҲ¶зҡ„еҚ•е…ғпјүпјҢдёҖдёӘеҲ—ж—ҸйҮҢзҡ„еҲ—дёҖиҲ¬еӯҳеӮЁзӣёеҗҢзұ»еһӢзҡ„ж•°жҚ®гҖӮдёҖиЎҢзҡ„еҲ—ж—ҸеҫҲе°‘еҸҳеҢ–пјҢдҪҶжҳҜеҲ—ж—ҸйҮҢзҡ„еҲ—еҸҜд»ҘйҡҸж„Ҹж·»еҠ еҲ йҷӨгҖӮеҲ—й”®жҢүз…§ family:qualifierж јејҸе‘ҪеҗҚзҡ„гҖӮиҝҷж¬ЎжҲ‘们е°ҶеҲ—жӢҝеҮәжқҘпјҢе°Ҷж—¶й—ҙе’ҢеҖјзңӢжҲҗдёҖдёӘж•ҙдҪ“пјҢз®ҖеҢ–дёәдәҢз»ҙй”®еҖјжҳ е°„пјҢзұ»дјјдәҺпјҡ
- table{В В
- В В //В ...В В
- В В "aaaaa"В :В {В //дёҖиЎҢВ В
- В В В В "A:foo"В :В {sth.},//дёҖеҲ—В В
- В В В В "A:bar"В :В {sth.},//дёҖеҲ—В В
- В В В В "B:"В :В {sth.}В //дёҖеҲ—пјҢеҲ—ж—ҸеҗҚдёәBпјҢдҪҶжҳҜеҲ—еҗҚжҳҜз©әеӯ—дёІВ В
- В В },В В
- В В "aaaab"В :В {В //дёҖиЎҢВ В
- В В В В "A:foo"В :В {sth.},В В
- В В В В "B:"В :В {sth.}В В
- В В },В В
- В В //В ...В В
- }В В
жҲ–иҖ…еҸҜд»Ҙе°ҶеҲ—ж—ҸеҪ“дҪңдёҖеұӮж–°зҡ„зҙўеј•пјҢзұ»дјјдәҺпјҡ
- table{В В
- В В //В ...В В
- В В "aaaaa"В :В {В //дёҖиЎҢВ В
- В В В В "A"В :В {В //еҲ—ж—ҸAВ В
- В В В В В В "foo"В :В {sth.},В //дёҖеҲ—В В
- В В В В В В "bar"В :В {sth.}В В
- В В В В },В В
- В В В В "B"В :В {В //еҲ—ж—ҸBВ В
- В В В В В В ""В :В {sth.}В В
- В В В В }В В
- В В },В В
- В В "aaaab"В :В {В //дёҖиЎҢВ В
- В В В В "A"В :В {В В
- В В В В В В "foo"В :В {sth.},В В
- В В В В },В В
- В В В В "B"В :В {В В
- В В В В В В ""В :В "ocean"В В
- В В В В }В В
- В В },В В
- В В //В ...В В
- }В В
ж—¶ й—ҙжҲіжҳҜ第дёүзә§зҙўеј•гҖӮBigtableе…Ғи®ёдҝқеӯҳж•°жҚ®зҡ„еӨҡдёӘзүҲжң¬пјҢзүҲжң¬еҢәеҲҶзҡ„дҫқжҚ®е°ұжҳҜж—¶й—ҙжҲігҖӮж—¶й—ҙжҲіеҸҜд»Ҙз”ұBigtableиөӢеҖјпјҢд»ЈиЎЁж•°жҚ®иҝӣе…Ҙ Bigtableзҡ„еҮҶзЎ®ж—¶й—ҙпјҢд№ҹеҸҜд»Ҙз”ұе®ўжҲ·з«ҜиөӢеҖјгҖӮж•°жҚ®зҡ„дёҚеҗҢзүҲжң¬жҢүз…§ж—¶й—ҙжҲійҷҚеәҸеӯҳеӮЁпјҢеӣ жӯӨе…ҲиҜ»еҲ°зҡ„жҳҜжңҖж–°зүҲжң¬зҡ„ж•°жҚ®гҖӮжҲ‘们еҠ е…Ҙж—¶й—ҙжҲіеҗҺпјҢе°ұеҫ—еҲ°дәҶ Bigtableзҡ„е®Ңж•ҙж•°жҚ®жЁЎеһӢпјҢзұ»дјјдәҺпјҡ
- table{В В
- В В //В ...В В
- В В "aaaaa"В :В {В //дёҖиЎҢВ В
- В В В В "A:foo"В :В {В //дёҖеҲ—В В
- В В В В В В В В 15В :В "y",В //дёҖдёӘзүҲжң¬В В
- В В В В В В В В 4В :В "m"В В
- В В В В В В },В В
- В В В В "A:bar"В :В {В //дёҖеҲ—В В
- В В В В В В В В 15В :В "d",В В
- В В В В В В },В В
- В В В В "B:"В :В {В //дёҖеҲ—В В
- В В В В В В В В 6В :В "w"В В
- В В В В В В В В 3В :В "o"В В
- В В В В В В В В 1В :В "w"В В
- В В В В В В }В В
- В В },В В
- В В //В ...В В
- }В В
жҹҘиҜўж—¶пјҢеҰӮжһңеҸӘз»ҷеҮәиЎҢеҲ—пјҢйӮЈд№Ҳиҝ”еӣһзҡ„жҳҜжңҖж–°зүҲжң¬зҡ„ж•°жҚ®пјӣеҰӮжһңз»ҷеҮәдәҶиЎҢеҲ—ж—¶й—ҙжҲіпјҢйӮЈд№Ҳиҝ”еӣһзҡ„жҳҜж—¶й—ҙе°ҸдәҺжҲ–зӯүдәҺж—¶й—ҙжҲізҡ„ж•°жҚ®гҖӮжҜ”еҰӮпјҢжҲ‘们жҹҘиҜў"aaaaa"/"A:foo"пјҢиҝ”еӣһзҡ„еҖјжҳҜ"y"пјӣжҹҘиҜў"aaaaa"/"A:foo"/10пјҢиҝ”еӣһзҡ„з»“жһңе°ұжҳҜ"m"пјӣжҹҘиҜў"aaaaa"/"A:foo"/2пјҢиҝ”еӣһзҡ„з»“жһңжҳҜз©әгҖӮ
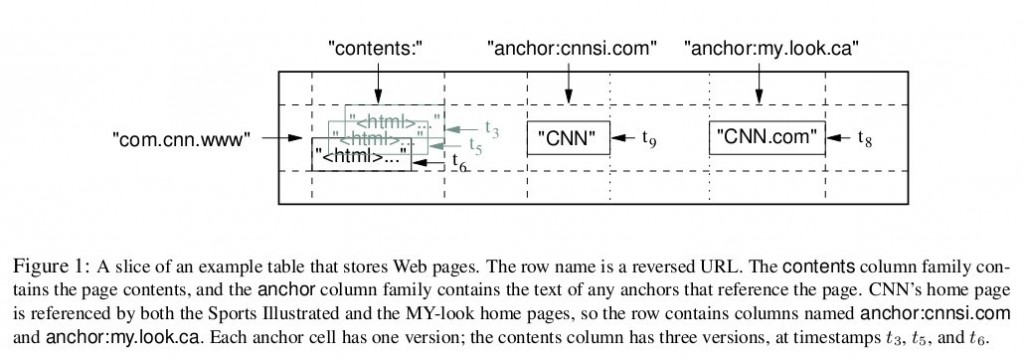
еӣҫ 1жҳҜBigtableи®әж–ҮйҮҢз»ҷеҮәзҡ„дҫӢеӯҗпјҢWebtableиЎЁеӯҳеӮЁдәҶеӨ§йҮҸзҡ„зҪ‘йЎөе’Ңзӣёе…ідҝЎжҒҜгҖӮеңЁWebtableпјҢжҜҸдёҖиЎҢеӯҳеӮЁдёҖдёӘзҪ‘йЎөпјҢе…¶еҸҚиҪ¬зҡ„urlдҪңдёәиЎҢ й”®пјҢжҜ”еҰӮmaps.google.com/index.htmlзҡ„ж•°жҚ®еӯҳеӮЁеңЁй”®дёәcom.google.maps/index.htmlзҡ„иЎҢйҮҢпјҢеҸҚиҪ¬зҡ„еҺҹ еӣ жҳҜдёәдәҶи®©еҗҢдёҖдёӘеҹҹеҗҚдёӢзҡ„еӯҗеҹҹеҗҚзҪ‘йЎөиғҪиҒҡйӣҶеңЁдёҖиө·гҖӮеӣҫ1дёӯзҡ„еҲ—ж—Ҹ"anchor"дҝқеӯҳдәҶиҜҘзҪ‘йЎөзҡ„еј•з”Ёз«ҷзӮ№пјҲжҜ”еҰӮеј•з”ЁдәҶCNNдё»йЎөзҡ„з«ҷзӮ№пјүпјҢqualifierжҳҜеј•з”Ёз«ҷзӮ№зҡ„еҗҚз§°пјҢиҖҢж•°жҚ®жҳҜй“ҫжҺҘж–Үжң¬пјӣеҲ—ж—Ҹ"contents"дҝқеӯҳзҡ„жҳҜзҪ‘йЎөзҡ„еҶ…е®№пјҢиҝҷдёӘеҲ—ж—ҸеҸӘжңүдёҖдёӘз©әеҲ—"contents:"гҖӮеӣҫ1дёӯ"contents:"еҲ—дёӢдҝқеӯҳдәҶзҪ‘йЎөзҡ„дёүдёӘзүҲжң¬пјҢжҲ‘们еҸҜд»Ҙз”Ё("com.cnn.www", "contents:", t5)жқҘжүҫеҲ°CNNдё»йЎөеңЁt5ж—¶еҲ»зҡ„еҶ…е®№гҖӮ
еҶҚжқҘзңӢзңӢдҪңиҖ…иҜҙзҡ„е…¶е®ғзү№еҫҒпјҡзЁҖз–ҸпјҢеҲҶеёғејҸпјҢжҢҒд№…еҢ–гҖӮжҢҒд№…еҢ–зҡ„ж„ҸжҖқеҫҲз®ҖеҚ•пјҢBigtableзҡ„ж•°жҚ®жңҖз»Ҳдјҡд»Ҙж–Ү件зҡ„еҪўејҸж”ҫеҲ°GFSеҺ»гҖӮBigtableе»әз«ӢеңЁGFSд№ӢдёҠжң¬иә«е°ұж„Ҹе‘ізқҖеҲҶеёғејҸпјҢеҪ“然еҲҶеёғејҸзҡ„ж„Ҹд№үиҝҳдёҚд»…йҷҗдәҺжӯӨгҖӮзЁҖз–Ҹзҡ„ж„ҸжҖқжҳҜпјҢдёҖдёӘиЎЁйҮҢдёҚеҗҢзҡ„иЎҢпјҢеҲ—еҸҜиғҪе®Ңе®Ңе…Ёе…ЁдёҚдёҖж ·гҖӮ
3 ж”Ҝж’‘жҠҖжңҜ
Bigtableдҫқиө–дәҺgoogleзҡ„еҮ йЎ№жҠҖжңҜгҖӮз”ЁGFSжқҘеӯҳеӮЁж—Ҙеҝ—е’Ңж•°жҚ®ж–Ү件пјӣжҢүSSTableж–Үд»¶ж јејҸеӯҳеӮЁж•°жҚ®пјӣз”ЁChubbyз®ЎзҗҶе…ғж•°жҚ®гҖӮ
GFSеҸӮи§Ғи°·жӯҢжҠҖжңҜ"дёүе®қ"д№Ӣи°·жӯҢж–Ү件系з»ҹгҖӮBigTableзҡ„ж•°жҚ®е’Ңж—Ҙеҝ—йғҪжҳҜеҶҷе…ҘGFSзҡ„гҖӮ
SSTableзҡ„е…Ёз§°жҳҜSorted Strings TableпјҢжҳҜ дёҖз§ҚдёҚеҸҜдҝ®ж”№зҡ„жңүеәҸзҡ„й”®еҖјжҳ е°„пјҢжҸҗдҫӣдәҶжҹҘиҜўгҖҒйҒҚеҺҶзӯүеҠҹиғҪгҖӮжҜҸдёӘSSTableз”ұдёҖзі»еҲ—зҡ„еқ—пјҲblockпјүз»„жҲҗпјҢBigtableе°Ҷеқ—й»ҳи®Өи®ҫдёә64KBгҖӮеңЁ SSTableзҡ„е°ҫйғЁеӯҳеӮЁзқҖеқ—зҙўеј•пјҢеңЁи®ҝй—®SSTableж—¶пјҢж•ҙдёӘзҙўеј•дјҡиў«иҜ»е…ҘеҶ…еӯҳгҖӮBigTableи®әж–ҮжІЎжңүжҸҗеҲ°SSTableзҡ„е…·дҪ“з»“жһ„пјҢLevelDbж—ҘзҹҘеҪ•д№Ӣеӣӣпјҡ SSTableж–Ү件иҝҷзҜҮж–Үз« еҜ№LevelDbзҡ„SSTableж јејҸиҝӣиЎҢдәҶд»Ӣз»ҚпјҢеӣ дёәLevelDBзҡ„дҪңиҖ…JeffreyDeanжӯЈжҳҜBigTableзҡ„и®ҫи®ЎеёҲпјҢжүҖд»ҘжһҒе…·еҸӮиҖғд»·еҖјгҖӮжҜҸдёҖдёӘзүҮпјҲtabletпјүеңЁGFSйҮҢйғҪжҳҜжҢүз…§SSTableзҡ„ж јејҸеӯҳеӮЁзҡ„пјҢжҜҸдёӘзүҮеҸҜиғҪеҜ№еә”еӨҡдёӘSSTableгҖӮ
ChubbyжҳҜдёҖз§Қй«ҳеҸҜз”Ёзҡ„еҲҶеёғејҸй”ҒжңҚ еҠЎпјҢChubbyжңүдә”дёӘжҙ»и·ғеүҜжң¬пјҢеҗҢж—¶еҸӘжңүдёҖдёӘдё»еүҜжң¬жҸҗдҫӣжңҚеҠЎпјҢеүҜжң¬д№Ӣй—ҙз”ЁPaxosз®—жі•з»ҙжҢҒдёҖиҮҙжҖ§пјҢChubbyжҸҗдҫӣдәҶдёҖдёӘе‘ҪеҗҚз©әй—ҙпјҲеҢ…жӢ¬дёҖдәӣзӣ®еҪ•е’Ңж–Ү 件пјүпјҢжҜҸдёӘзӣ®еҪ•е’Ңж–Ү件е°ұжҳҜдёҖдёӘй”ҒпјҢChubbyзҡ„е®ўжҲ·з«Ҝеҝ…йЎ»е’ҢChubbyдҝқжҢҒдјҡиҜқпјҢе®ўжҲ·з«Ҝзҡ„дјҡиҜқиӢҘиҝҮжңҹеҲҷдјҡдёўеӨұжүҖжңүзҡ„й”ҒгҖӮе…ідәҺChubbyзҡ„иҜҰз»ҶдҝЎжҒҜеҸҜ д»ҘзңӢgoogleзҡ„еҸҰдёҖзҜҮи®әж–ҮпјҡThe Chubby lock service for loosely-coupled distributed systemsгҖӮChubbyз”ЁдәҺзүҮе®ҡдҪҚпјҢзүҮжңҚеҠЎеҷЁзҡ„зҠ¶жҖҒзӣ‘жҺ§пјҢи®ҝй—®жҺ§еҲ¶еҲ—иЎЁеӯҳеӮЁзӯүд»»еҠЎгҖӮ
4 BigtableйӣҶзҫӨ
BigtableйӣҶзҫӨеҢ…жӢ¬дёүдёӘдё»иҰҒйғЁеҲҶпјҡдёҖдёӘдҫӣе®ўжҲ·з«ҜдҪҝз”Ёзҡ„еә“пјҢдёҖдёӘдё»жңҚеҠЎеҷЁпјҲmaster serverпјүпјҢи®ёеӨҡзүҮжңҚеҠЎеҷЁпјҲtablet serverпјүгҖӮ
жӯЈеҰӮж•°жҚ®жЁЎеһӢе°ҸиҠӮжүҖиҜҙпјҢBigtableдјҡе°ҶиЎЁпјҲtableпјүиҝӣиЎҢеҲҶзүҮпјҢзүҮпјҲtabletпјүзҡ„еӨ§е°Ҹз»ҙжҢҒеңЁ100-200MBиҢғеӣҙпјҢдёҖж—Ұи¶…еҮәиҢғеӣҙе°ұе°ҶеҲҶиЈӮжҲҗжӣҙе°Ҹзҡ„зүҮпјҢжҲ–иҖ…еҗҲ并жҲҗжӣҙеӨ§зҡ„зүҮгҖӮжҜҸдёӘзүҮжңҚеҠЎеҷЁиҙҹиҙЈдёҖе®ҡйҮҸзҡ„зүҮпјҢеӨ„зҗҶеҜ№е…¶зүҮзҡ„иҜ»еҶҷиҜ·жұӮпјҢд»ҘеҸҠзүҮзҡ„еҲҶиЈӮжҲ–еҗҲ并гҖӮзүҮжңҚеҠЎеҷЁеҸҜд»Ҙж №жҚ®иҙҹиҪҪйҡҸж—¶ж·»еҠ е’ҢеҲ йҷӨгҖӮиҝҷйҮҢзүҮжңҚеҠЎеҷЁе№¶дёҚзңҹе®һеӯҳеӮЁж•°жҚ®пјҢиҖҢзӣёеҪ“дәҺдёҖдёӘиҝһжҺҘBigtableе’ҢGFSзҡ„д»ЈзҗҶпјҢе®ўжҲ·з«Ҝзҡ„дёҖдәӣж•°жҚ®ж“ҚдҪңйғҪйҖҡиҝҮзүҮжңҚеҠЎеҷЁд»ЈзҗҶй—ҙжҺҘи®ҝй—®GFSгҖӮ
дё»жңҚеҠЎеҷЁиҙҹиҙЈе°ҶзүҮеҲҶй…Қз»ҷзүҮжңҚеҠЎеҷЁпјҢзӣ‘жҺ§зүҮжңҚеҠЎеҷЁзҡ„ж·»еҠ е’ҢеҲ йҷӨпјҢе№іиЎЎзүҮжңҚеҠЎеҷЁзҡ„иҙҹиҪҪпјҢеӨ„зҗҶиЎЁе’ҢеҲ—ж—Ҹзҡ„еҲӣе»әзӯүгҖӮжіЁж„ҸпјҢдё»жңҚеҠЎеҷЁдёҚеӯҳеӮЁд»»дҪ•зүҮпјҢдёҚжҸҗдҫӣд»»дҪ•ж•°жҚ®жңҚеҠЎпјҢд№ҹдёҚжҸҗдҫӣзүҮзҡ„е®ҡдҪҚдҝЎжҒҜгҖӮ
е®ўжҲ·з«ҜйңҖиҰҒиҜ»еҶҷж•°жҚ®ж—¶пјҢзӣҙжҺҘдёҺзүҮжңҚеҠЎеҷЁиҒ”зі»гҖӮеӣ дёәе®ўжҲ·з«Ҝ并дёҚйңҖиҰҒд»Һдё»жңҚеҠЎеҷЁиҺ·еҸ–зүҮзҡ„дҪҚзҪ®дҝЎжҒҜпјҢжүҖд»ҘеӨ§еӨҡж•°е®ўжҲ·з«Ҝд»ҺжқҘдёҚйңҖиҰҒи®ҝй—®дё»жңҚеҠЎеҷЁпјҢдё»жңҚеҠЎеҷЁзҡ„иҙҹиҪҪдёҖиҲ¬еҫҲиҪ»гҖӮ
5 зүҮзҡ„е®ҡдҪҚ
еүҚйқўжҸҗеҲ°дё»жңҚеҠЎеҷЁдёҚжҸҗдҫӣзүҮзҡ„дҪҚзҪ®дҝЎжҒҜпјҢйӮЈд№Ҳе®ўжҲ·з«ҜжҳҜеҰӮдҪ•и®ҝй—®зүҮзҡ„е‘ўпјҹжқҘзңӢзңӢи®әж–Үз»ҷзҡ„зӨәж„ҸеӣҫпјҢBigtableдҪҝз”ЁдёҖдёӘзұ»дјјB+ж ‘зҡ„ж•°жҚ®з»“жһ„еӯҳеӮЁзүҮзҡ„дҪҚзҪ®дҝЎжҒҜгҖӮ
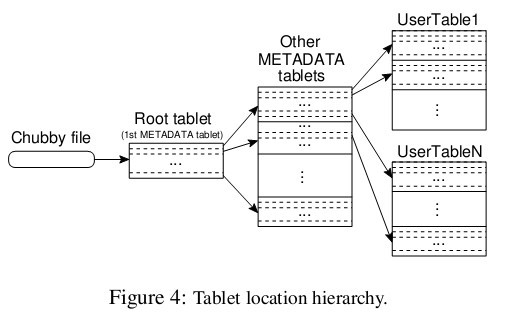
йҰ–е…ҲжҳҜ第дёҖеұӮпјҢChubby fileгҖӮиҝҷдёҖеұӮжҳҜдёҖдёӘChubbyж–Ү件пјҢе®ғдҝқеӯҳзқҖroot tabletзҡ„дҪҚзҪ®гҖӮиҝҷдёӘChubbyж–Ү件еұһдәҺChubbyжңҚеҠЎзҡ„дёҖйғЁеҲҶпјҢдёҖж—ҰChubbyдёҚеҸҜз”ЁпјҢе°ұж„Ҹе‘ізқҖдёўеӨұдәҶroot tabletзҡ„дҪҚзҪ®пјҢж•ҙдёӘBigtableд№ҹе°ұдёҚеҸҜз”ЁдәҶгҖӮ
第дәҢеұӮжҳҜroot tabletгҖӮroot tabletе…¶е®һжҳҜе…ғж•°жҚ®иЎЁпјҲMETADATA tableпјүзҡ„第дёҖдёӘеҲҶзүҮпјҢе®ғдҝқеӯҳзқҖе…ғж•°жҚ®иЎЁе…¶е®ғзүҮзҡ„дҪҚзҪ®гҖӮroot tabletеҫҲзү№еҲ«пјҢдёәдәҶдҝқиҜҒж ‘зҡ„ж·ұеәҰдёҚеҸҳпјҢroot tabletд»ҺдёҚеҲҶиЈӮгҖӮ
第дёүеұӮжҳҜе…¶е®ғзҡ„е…ғж•°жҚ®зүҮпјҢе®ғ们е’Ңroot tabletдёҖиө·з»„жҲҗе®Ңж•ҙзҡ„е…ғж•°жҚ®иЎЁгҖӮжҜҸдёӘе…ғж•°жҚ®зүҮйғҪеҢ…еҗ«дәҶи®ёеӨҡз”ЁжҲ·зүҮзҡ„дҪҚзҪ®дҝЎжҒҜгҖӮ
еҸҜд»ҘзңӢеҮәж•ҙдёӘе®ҡдҪҚзі»з»ҹе…¶е®һеҸӘжҳҜдёӨйғЁеҲҶпјҢдёҖдёӘChubbyж–Ү件пјҢдёҖдёӘе…ғж•°жҚ®иЎЁгҖӮжіЁж„Ҹе…ғж•°жҚ®иЎЁиҷҪ然зү№ж®ҠпјҢдҪҶд№ҹд»Қ然жңҚд»ҺеүҚж–Үзҡ„ж•°жҚ®жЁЎеһӢпјҢжҜҸдёӘеҲҶзүҮд№ҹйғҪжҳҜз”ұдё“й—Ёзҡ„зүҮжңҚеҠЎеҷЁиҙҹиҙЈпјҢиҝҷе°ұжҳҜдёҚйңҖиҰҒдё»жңҚеҠЎеҷЁжҸҗдҫӣдҪҚзҪ®дҝЎжҒҜзҡ„еҺҹеӣ гҖӮе®ўжҲ·з«Ҝдјҡзј“еӯҳзүҮзҡ„дҪҚзҪ®дҝЎжҒҜпјҢеҰӮжһңеңЁзј“еӯҳйҮҢжүҫдёҚеҲ°дёҖдёӘзүҮзҡ„дҪҚзҪ®дҝЎжҒҜпјҢе°ұйңҖиҰҒжҹҘжүҫиҝҷдёӘдёүеұӮз»“жһ„дәҶпјҢеҢ…жӢ¬и®ҝй—®дёҖж¬ЎChubbyжңҚеҠЎпјҢи®ҝй—®дёӨж¬ЎзүҮжңҚеҠЎеҷЁгҖӮ
6 зүҮзҡ„еӯҳеӮЁе’Ңи®ҝй—®

еҪ“зүҮжңҚеҠЎеҷЁ 收еҲ°дёҖдёӘеҶҷиҜ·жұӮпјҢзүҮжңҚеҠЎеҷЁйҰ–е…ҲжЈҖжҹҘиҜ·жұӮжҳҜеҗҰеҗҲжі•гҖӮеҰӮжһңеҗҲжі•пјҢе…Ҳе°ҶеҶҷиҜ·жұӮжҸҗдәӨеҲ°ж—Ҙеҝ—еҺ»пјҢ然еҗҺе°Ҷж•°жҚ®еҶҷе…ҘеҶ…еӯҳдёӯзҡ„memtableгҖӮmemtableзӣёеҪ“дәҺ SSTableзҡ„зј“еӯҳпјҢеҪ“memtableжҲҗй•ҝеҲ°дёҖе®ҡ规模дјҡиў«еҶ»з»“пјҢBigtableйҡҸд№ӢеҲӣе»әдёҖдёӘж–°зҡ„memtableпјҢ并且е°ҶеҶ»з»“зҡ„memtableиҪ¬ жҚўдёәSSTableж јејҸеҶҷе…ҘGFSпјҢиҝҷдёӘж“ҚдҪңз§°дёәminor compactionгҖӮ
еҪ“зүҮжңҚеҠЎеҷЁж”¶еҲ°дёҖдёӘиҜ»иҜ·жұӮпјҢеҗҢж ·иҰҒжЈҖжҹҘиҜ·жұӮжҳҜеҗҰеҗҲжі•гҖӮеҰӮжһңеҗҲжі•пјҢиҝҷдёӘиҜ»ж“ҚдҪңдјҡжҹҘзңӢжүҖжңүSSTableж–Ү件е’Ңmemtableзҡ„еҗҲ并и§ҶеӣҫпјҢеӣ дёәSSTableе’Ңmemtableжң¬иә«йғҪжҳҜе·ІжҺ’еәҸзҡ„пјҢжүҖд»ҘеҗҲ并зӣёеҪ“еҝ«гҖӮ
жҜҸдёҖж¬Ўminor compactionйғҪдјҡдә§з”ҹдёҖдёӘж–°зҡ„SSTableж–Ү件пјҢSSTableж–Ү件еӨӘеӨҡиҜ»ж“ҚдҪңзҡ„ж•ҲзҺҮе°ұйҷҚдҪҺдәҶпјҢжүҖд»ҘBigtableе®ҡжңҹжү§иЎҢmerging compactionж“ҚдҪңпјҢе°ҶеҮ дёӘSSTableе’ҢmemtableеҗҲ并дёәдёҖдёӘж–°зҡ„SSTableгҖӮBigTableиҝҳжңүдёӘжӣҙеҺүе®ізҡ„еҸ«major compactionпјҢе®ғе°ҶжүҖжңүSSTableеҗҲ并дёәдёҖдёӘж–°зҡ„SSTableгҖӮ
йҒ—жҶҫзҡ„жҳҜпјҢBigTableдҪңиҖ…жІЎжңүд»Ӣз»Қmemtableе’ҢSSTableзҡ„иҜҰз»Ҷж•°жҚ®з»“жһ„гҖӮ
7 BigTableе’ҢGFSзҡ„е…ізі»
йӣҶзҫӨеҢ…жӢ¬дё»жңҚеҠЎеҷЁе’ҢзүҮжңҚеҠЎеҷЁпјҢдё»жңҚеҠЎеҷЁиҙҹиҙЈе°ҶзүҮеҲҶй…Қз»ҷ зүҮжңҚеҠЎеҷЁпјҢиҖҢе…·дҪ“зҡ„ж•°жҚ®жңҚеҠЎеҲҷе…Ёжқғз”ұзүҮжңҚеҠЎеҷЁиҙҹиҙЈгҖӮдҪҶжҳҜдёҚиҰҒиҜҜд»ҘдёәзүҮжңҚеҠЎеҷЁзңҹзҡ„еӯҳеӮЁдәҶж•°жҚ®пјҲйҷӨдәҶеҶ…еӯҳдёӯmemtableзҡ„ж•°жҚ®пјүпјҢж•°жҚ®зҡ„зңҹе®һдҪҚзҪ®еҸӘжңү GFSжүҚзҹҘйҒ“пјҢдё»жңҚеҠЎеҷЁе°ҶзүҮеҲҶй…Қз»ҷзүҮжңҚеҠЎеҷЁзҡ„ж„ҸжҖқеә”иҜҘжҳҜпјҢзүҮжңҚеҠЎеҷЁиҺ·еҸ–дәҶзүҮзҡ„жүҖжңүSSTableж–Ү件еҗҚпјҢзүҮжңҚеҠЎеҷЁйҖҡиҝҮдёҖдәӣзҙўеј•жңәеҲ¶еҸҜд»ҘзҹҘйҒ“жүҖйңҖиҰҒзҡ„ж•°жҚ®еңЁ е“ӘдёӘSSTableж–Ү件пјҢ然еҗҺд»ҺGFSдёӯиҜ»еҸ–SSTableж–Ү件зҡ„ж•°жҚ®пјҢиҝҷдёӘSSTableж–Ү件еҸҜиғҪеҲҶеёғеңЁеҘҪеҮ еҸ°chunkserverдёҠгҖӮ
8 е…ғж•°жҚ®иЎЁзҡ„з»“жһ„
е…ғж•°жҚ®иЎЁпјҲMETADATA tableпјүжҳҜдёҖеј зү№ж®Ҡзҡ„иЎЁпјҢе®ғиў«з”ЁдәҺж•°жҚ®зҡ„е®ҡдҪҚд»ҘеҸҠдёҖдәӣе…ғж•°жҚ®жңҚеҠЎпјҢдёҚеҸҜи°“дёҚйҮҚиҰҒгҖӮдҪҶжҳҜBigtableи®әж–ҮйҮҢеҸӘз»ҷеҮәдәҶе°‘йҮҸзәҝзҙўпјҢиҖҢеҜ№иЎЁзҡ„е…·дҪ“з»“жһ„жІЎжңүиҜҙжҳҺгҖӮиҝҷйҮҢжҲ‘иҜ•еӣҫж №жҚ®и®әж–Үзҡ„дёҖдәӣзәҝзҙўпјҢзҢңжөӢдёҖдёӢиЎЁзҡ„з»“жһ„гҖӮйҰ–е…ҲеҲ—еҮәи®әж–Үдёӯзҡ„зәҝзҙўпјҡ
- The METADATA table stores the location of a tabletВ under a row key that is an encoding of the tablet's tableВ identifier and its end row.
- Each METADATA row storesВ approximately 1KB of data in memoryпјҲеӣ дёәи®ҝй—®йҮҸжҜ”иҫғеӨ§пјҢе…ғж•°жҚ®иЎЁжҳҜж”ҫеңЁеҶ…еӯҳйҮҢзҡ„пјҢиҝҷдёӘдјҳеҢ–еңЁи®әж–Үзҡ„locality groupsдёӯжҸҗеҲ°пјү.This featureпјҲе°Ҷlocality groupж”ҫеҲ°еҶ…еӯҳдёӯзҡ„зү№жҖ§пјү is useful forВ small pieces of data that are accessed frequently: weВ use it internally for the location column family in theВ METADATA table.
- We also store secondary information in theВ METADATA table, including a log of all events pertaining to each tablet(such as when a server begins
serving it).
第дёҖжқЎзәҝзҙўпјҢе…ғж•°жҚ®иЎЁзҡ„иЎҢй”®жҳҜз”ұзүҮжүҖеұһиЎЁеҗҚзҡ„idе’ҢзүҮжңҖеҗҺдёҖиЎҢзј–з ҒиҖҢжҲҗпјҢжүҖд»ҘжҜҸдёӘзүҮеңЁе…ғж•°жҚ®иЎЁдёӯеҚ жҚ®дёҖжқЎи®°еҪ•пјҲдёҖиЎҢпјүпјҢиҖҢдё”иЎҢй”®ж—ўеҢ…еҗ«дәҶе…¶жүҖеұһиЎЁзҡ„дҝЎжҒҜд№ҹеҢ…еҗ«дәҶе…¶жүҖжӢҘжңүзҡ„иЎҢзҡ„иҢғеӣҙгҖӮиӯ¬еҰӮйҮҮеҸ–жңҖз®ҖеҚ•зҡ„зј–з Ғж–№ејҸпјҢе…ғж•°жҚ®иЎЁзҡ„иЎҢй”®зӯүдәҺstrcat(иЎЁеҗҚпјҢзүҮжңҖеҗҺдёҖиЎҢзҡ„иЎҢй”®)гҖӮ
第дәҢзӮ№зәҝзҙўпјҢйҷӨдәҶзҹҘйҒ“е…ғж•°жҚ®иЎЁзҡ„ең°еқҖйғЁеҲҶжҳҜеёёй©»еҶ…еӯҳд»Ҙ еӨ–пјҢиҝҳеҸҜд»ҘеҸ‘зҺ°е…ғж•°жҚ®иЎЁжңүдёҖдёӘеҲ—ж—Ҹз§°дёәlocationпјҢжҲ‘们已з»ҸзҹҘйҒ“е…ғж•°жҚ®иЎЁжҜҸдёҖиЎҢд»ЈиЎЁдёҖдёӘзүҮпјҢйӮЈд№Ҳдёәд»Җд№ҲйңҖиҰҒдёҖдёӘеҲ—ж—ҸжқҘеӯҳеӮЁең°еқҖе‘ўпјҹеӣ дёәжҜҸдёӘзүҮйғҪеҸҜиғҪ з”ұеӨҡдёӘSSTableж–Ү件组жҲҗпјҢеҲ—ж—ҸеҸҜд»Ҙз”ЁжқҘеӯҳеӮЁд»»ж„ҸеӨҡдёӘSSTableж–Ү件зҡ„дҪҚзҪ®гҖӮдёҖдёӘеҗҲзҗҶзҡ„еҒҮи®ҫе°ұжҳҜжҜҸдёӘSSTableж–Ү件зҡ„дҪҚзҪ®дҝЎжҒҜеҚ жҚ®дёҖеҲ—пјҢеҲ—еҗҚ дёәlocation:filenameгҖӮеҪ“然дёҚдёҖе®ҡйқһеҫ—з”ЁеҲ—й”®еӯҳеӮЁе®Ңж•ҙж–Ү件еҗҚпјҢжӣҙеӨ§зҡ„еҸҜиғҪжҖ§жҳҜжҠҠSSTableж–Ү件еҗҚеӯҳеңЁеҖјйҮҢгҖӮиҺ·еҸ–дәҶж–Ү件еҗҚе°ұеҸҜд»Ҙеҗ‘ GFSзҙўиҰҒж•°жҚ®дәҶгҖӮ
第дёүдёӘзәҝзҙўе‘ҠиҜүжҲ‘们е…ғж•°жҚ®иЎЁдёҚжӯўеӯҳеӮЁдҪҚзҪ®дҝЎжҒҜпјҢд№ҹе°ұжҳҜиҜҙеҲ—ж—ҸдёҚжӯўlocationпјҢиҝҷдәӣж•°жҚ®жҡӮж—¶дёҚжҳҜе’ұ们关еҝғзҡ„гҖӮ
йҖҡиҝҮд»ҘдёҠдҝЎжҒҜпјҢжҲ‘з”»дәҶдёҖдёӘз®ҖеҢ–зҡ„Bigtableз»“жһ„еӣҫпјҡ
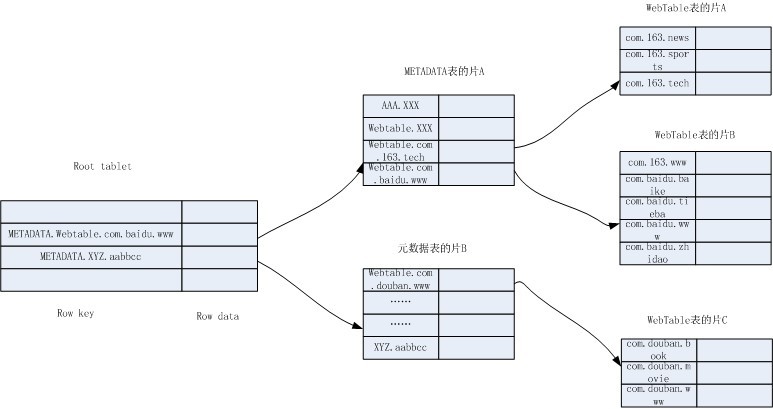
з»“жһ„еӣҫд»ҘWebtableиЎЁдёәдҫӢпјҢиЎЁдёӯеӯҳеӮЁдәҶзҪ‘жҳ“гҖҒзҷҫеәҰе’ҢиұҶз“Јзҡ„еҮ дёӘзҪ‘йЎөгҖӮеҪ“жҲ‘们жғіжҹҘжүҫзҷҫеәҰиҙҙеҗ§жҳЁеӨ©зҡ„зҪ‘йЎөеҶ…е®№пјҢеҸҜд»Ҙеҗ‘BigtableеҸ‘еҮәжҹҘиҜўWebtableиЎЁзҡ„(com.baidu.tieba, contents:, yesterday)гҖӮ
еҒҮи®ҫе®ўжҲ·з«ҜжІЎжңүиҜҘзј“еӯҳпјҢйӮЈд№ҲBigtableи®ҝй—® root tabletзҡ„зүҮжңҚеҠЎеҷЁпјҢеёҢжңӣеҫ—еҲ°иҜҘзҪ‘йЎөжүҖеұһзҡ„зүҮзҡ„дҪҚзҪ®дҝЎжҒҜеңЁе“ӘдёӘе…ғж•°жҚ®зүҮдёӯгҖӮдҪҝз”ЁMETADATA.Webtable.com.baidu.tieba дёәиЎҢй”®еңЁroot tabletдёӯжҹҘжүҫпјҢе®ҡдҪҚеҲ°жңҖеҗҺдёҖдёӘжҜ”е®ғеӨ§зҡ„жҳҜMETADATA.Webtable.com.baidu.wwwпјҢдәҺжҳҜзЎ®е®ҡйңҖиҰҒзҡ„е°ұжҳҜе…ғж•°жҚ®иЎЁзҡ„зүҮAгҖӮи®ҝ й—®зүҮAзҡ„зүҮжңҚеҠЎеҷЁпјҢ继з»ӯжҹҘжүҫWebtable.com.baidu.tiebaпјҢе®ҡдҪҚеҲ°Webtable.com.baidu.wwwжҳҜжҜ”е®ғеӨ§зҡ„пјҢзЎ®е®ҡйңҖ иҰҒзҡ„жҳҜWebtableиЎЁзҡ„зүҮBгҖӮи®ҝй—®зүҮBзҡ„зүҮжңҚеҠЎеҷЁпјҢиҺ·еҫ—ж•°жҚ®гҖӮ
еЈ°жҳҺ: жң¬ж–Үз”ұ( зҲұиҜҙдә‘зҪ‘ )еҺҹеҲӣзј–иҜ‘пјҢиҪ¬иҪҪиҜ·дҝқз•ҷй“ҫжҺҘ: и°·жӯҢжҠҖжңҜ”дёүе®қ”д№ӢBigTable — еӨ§ж•°жҚ®дә‘и®Ўз®—ж—¶д»Ј
и°·жӯҢжҠҖжңҜ”дёүе®қ”д№ӢBigTable — еӨ§ж•°жҚ®дә‘и®Ўз®—ж—¶д»ЈпјҡзӯүжӮЁеқҗжІҷеҸ‘е‘ўпјҒ
еҸ‘иЎЁиҜ„и®ә
- й«ҳеҸҜз”ЁдёҺиҙҹиҪҪеқҮиЎЎзҡ„еҢәеҲ«
- lampжһ¶жһ„еёҲеҝ…зңӢз»Ҹе…ё
- еӯҳеӮЁжһҒе®ў | еҶҚдёҚжӢҘжҠұDockerе®№еҷЁпјҢдҪ зҡ„...
- е®һж–ҪеҲӣж–°й©ұеҠЁеҸ‘еұ•жҲҳз•ҘпјҢжҺЁеҠЁдјҒдёҡеҸ‘еұ•
- еӨ§ж•°жҚ®е…Ҙдҫөйҡҗз§Ғпјҡиў«еҚ–иҝҳдёҚз®—пјҢй’ұиўӢд№ҹиў«...
- дёәд»Җд№ҲеҫҲеӨҡSaaSдјҒдёҡзә§дә§е“ҒйғҪзҶ¬дёҚиҝҮ第...
- дәҡ马йҖҠдә‘и®Ўз®—дёӯеҝғдёәдҪ•зңӢдёҠе®ҒеӨҸдёӯеҚ«пјҹ
- еҰӮдҪ•зІҫеҝғи®ҫи®ЎCDNжһ¶жһ„пјҹ
- Linuxиҝҗз»ҙпјҡзҺ°зҠ¶гҖҒе…Ҙй—Ёе’ҢжңӘжқҘд№Ӣи·Ҝ
- shellи„ҡжң¬дёӯдёҖдәӣзү№ж®Ҡз¬ҰеҸ·
- дҪҝз”ЁVirtualBoxжһ„е»әCloudStackжөӢиҜ•...
- жһ„е»әејҖжәҗз§Ғжңүдә‘еҲ©ејҠеҲҶжһҗ
- и§ЈиҜ»дёүеӨ§ж•°жҚ®дёӯеҝғзҪ‘з»ңжҠҖжңҜпјҡдёәдә‘и®Ўз®—иҖҢ...
- Googleж•ҙеҗҲStackDriverжҠҖжңҜпјҡеҗ‘ејҖеҸ‘...
- зӣҳзӮ№ж•°жҚ®еә“2014пјҡдёҖжӯҘд№ӢйҒҘеҲ°дә‘з«Ҝ
- еӨ§иҜқзҷҪиҜқдә‘и®Ўз®—
- д»Һдә‘зҡ„иө·жәҗжө…жһҗеӣҪеҶ…дә‘е№іеҸ°зҡ„зҺ°зҠ¶е’ҢжңӘжқҘ
- Windows Azureе…¬жңүдә‘зӣҙж’ӯдё–з•ҢжқҜ
- еӨ®и§ҶжҗәйҳҝйҮҢдә‘и®Ўз®—жү“йҖ е…ЁзҪ‘жңҖеҝ«дё–з•ҢжқҜзӣҙ...
- дёәдә‘иҖҢеҸҳ Office 365еј•йўҶзҡ„е…ЁйқўиҪ¬еһӢ
- зҫҺеӣҪдёӨеӨ§дә’иҒ”зҪ‘е·ЁеӨҙеҠ еҝ«еҸ‘еұ•дә‘и®Ўз®—
- ж•ҷдҪ еҰӮдҪ•дҪҝз”ЁPaaSдҪңдёәе®үе…ЁжҺ§еҲ¶зҡ„иҜ•йӘҢ...
- дә‘и®Ўз®—пјҡзЁӢеәҸе‘ҳйҮҚеӣһдёӘдәәиӢұйӣ„ж—¶д»Ј -
- mongodbеӨҮд»Ҫе’ҢиҝҳеҺҹ
- е°ҸзұізҫҺзҡ„пјҡе……ж»ЎжңӘзҹҘзҡ„иҜ•жҺў
- 2015е№ҙ7еӨ§дә‘е®үе…Ёйў„жөӢ
- жҢ‘йҖүSaaSдјҒдёҡйңҖиҰҒжіЁж„ҸеҚҒиҰҒзҙ
- OpenStack Trove и·Ҝзәҝеӣҫ вҖ” OpenS...
- дә‘и®Ўз®—ж ёеҝғжҠҖжңҜеү–жһҗ
- дә‘и®Ўз®—жҳҜдёӯе°ҸдјҒдёҡе»әи®ҫдҝЎжҒҜеҢ–зҡ„е…ій”®
зғӯй—Ёж Үзӯҫ
- AWS Docker EC2 дә‘еӯҳеӮЁ дә‘е®үе…Ё дә‘еә”з”Ё дә‘и®Ўз®— дә‘и®Ўз®—дёҺдҝЎжҒҜеҢ– дә‘и®Ўз®—дёҺеӨ§ж•°жҚ® дә‘и®Ўз®—дёҺзү©иҒ”зҪ‘ дә‘и®Ўз®—е№іеҸ° дә‘и®Ўз®—еә”з”Ё дә‘и®Ўз®—еә”з”Ёе®һдҫӢ дә‘и®Ўз®—еә”з”ЁйўҶеҹҹ дә‘и®Ўз®—жҠҖжңҜ дә‘и®Ўз®—жҳҜд»Җд№Ҳ дә‘и®Ўз®—жҳҜд»Җд№Ҳж„ҸжҖқ дә‘и®Ўз®—зҪ‘ дә’иҒ”зҪ‘йҮ‘иһҚ дҝЎжҒҜеҢ– еӨ§ж•°жҚ® еӨ§ж•°жҚ® еӨ§ж•°жҚ®еҲҶжһҗ еӨ§ж•°жҚ®ж—¶д»Ј е№ҝе·һдә‘и®Ўз®—зҪ‘ зү©иҒ”зҪ‘ зңҹеҘҪдә‘и®Ўз®—зҪ‘ 移еҠЁдә’иҒ”зҪ‘ йҳҝйҮҢдә‘ йҳҝйҮҢдә‘и®Ўз®—